
多智能体强化学习历程
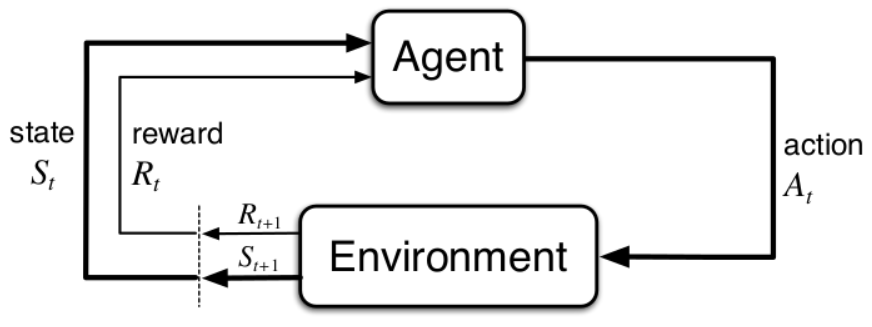
马尔科夫决策过程(MDP)
M=(S,A,R,P,γ)
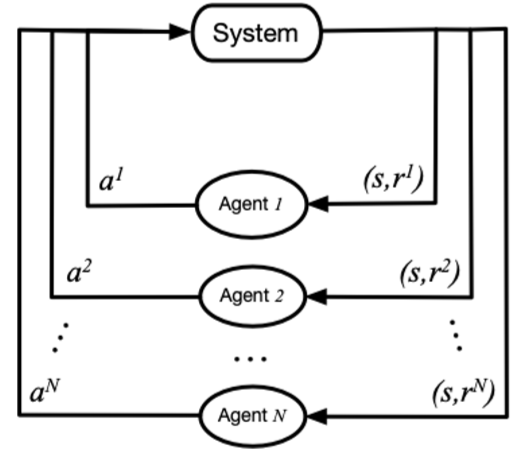
马尔科夫博弈(随机博弈)
M=< S,A1,…,An,T,R1,…,Rn >
某个智能体 i 获得的累积奖励的期望可以表示为:
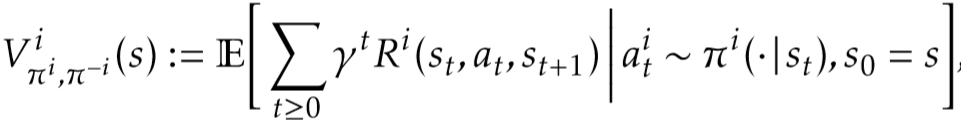
纳什均衡(Nash equilibrium):在多个智能体中达成的一个不动点,对于其中任意一个智能体来说,无法通过采取其他的策略来获得更高的累积回报,在数学形式上可以表达为:
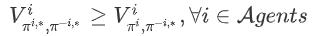
在该式中,$π^{i,}$表示智能体 i 的纳什均衡策略。纳什均衡不一定是全局最优,但它是在概率上最容易产生的结果,是在学习时较容易收敛到的状态。均衡求解方法是多智能体强化学习的基本方法。
遇到的问题与挑战
1) 环境的不稳定性:智能体在做决策的同时,其他智能体也在采取动作;环境状态的变化与所有智能体的联合动作相关;
2) 智能体获取信息的局限性:不一定能够获得全局的信息,智能体仅能获取局部的观测信息,但无法得知其他智能体的观测信息、动作和奖励等信息;
3) 个体的目标一致性:各智能体的目标可能是最优的全局回报;也可能是各自局部回报的最优;
4) 可拓展性:在大规模的多智能体系统中,就会涉及到高维度的状态空间和动作空间,对于模型表达能力和真实场景中的硬件算力有一定的要求。
算法介绍
1.完全竞争关系
minimax Q-learning
基于强化学习中的 Q-learning 方法,利用 minimax 思想定义的值函数、通过迭代更新 Q 值,而选择动作则是通过线性规划来求解当前阶段状态 s 对应的纳什均衡策略。

最优值函数的定义:对于智能体 i,它需要考虑在其他智能体(i-)采取的动作(a-)令自己(i)回报最差(min)的情况下,能够获得的最大(max)期望回报。该回报可以表示为:
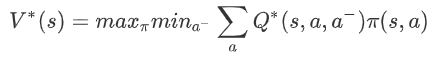
这个值函数表明,当前智能体在考虑了对手策略的情况下使用贪心选择,使得智能体容易收敛到纳什均衡策略。
伪代码

2.半合作半竞争关系
Nash Q-learning
每个智能体采用普通的 Q-Learning方法,并且都采取贪心的方式、即最大化各自的 Q 值时,这样的方法容易收敛到纳什均衡策略。Nash Q-learning 方法可用于处理以纳什均衡为解的多智能体学习问题。它的目标是通过寻找每一个状态的纳什均衡点,从而在学习过程中基于纳什均衡策略来更新 Q 值。
具体地,对于一个智能体 i 来说,它的 Nash Q 值定义为:
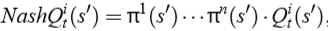
此时,假设了所有智能体从下一时刻开始都采取纳什均衡策略,纳什策略可以通过二次规划(仅考虑离散的动作空间,π是各动作的概率分布)来求解。
在 Q 值的迭代更新过程中,使用 Nash Q 值来更新:
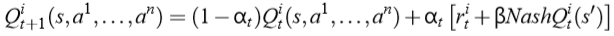
对于单个智能体 i,在使用 Nash Q 值进行更新时,它除了需要知道全局状态 s 和其他智能体的动作 a 以外,还需要知道其他所有智能体在下一状态对应的纳什均衡策略π。进一步地,当前智能体就需要知道其他智能体的 Q(s’)值,这通常是根据观察到的其他智能体的奖励和动作来猜想和计算。所以,Nash Q-learning 方法对智能体能够获取的其他智能体的信息(包括动作、奖励等)具有较强的假设,在复杂的真实问题中一般不满足这样严格的条件,方法的适用范围受限。
伪代码

3.完全合作关系
- 不需要协作机制
当所有智能体的联合最优动作是唯一的时候,完成该任务是不需要协作机制的。
Team Q-learning
对于单个智能体 i,可以通过下面这个式子来求出它的最优动作 hi:
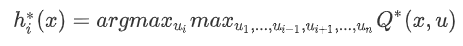
Distributed Q-learning
不同于 Team Q-learning 在选取个体最优动作的时候需要知道其他智能体的动作,在该方法中智能体维护的是只依据自身动作所对应的 Q 值,从而得到个体最优动作。
- 隐式的协作机制
基于平均场理论的多智能体强化学习(MFMARL)
将传统强化学习方法(Q-learning)和平均场理论(mean field theory)相结合。
建模思想:
对于其中的某个个体,所有其他个体产生的联合作用可以用一个 “平均量” 来定义和衡量。此时,对于其中一个个体来说,所有其他个体的影响相当于一个单体对于它的影响,这样的建模方式能够有效处理维度空间和计算量庞大的问题。
- 显式的协作机制
主要应用于人机之间的交互,考虑现存的一些约束条件 / 先验规则等
多智能体深度强化学习
1.policy-based 的方法
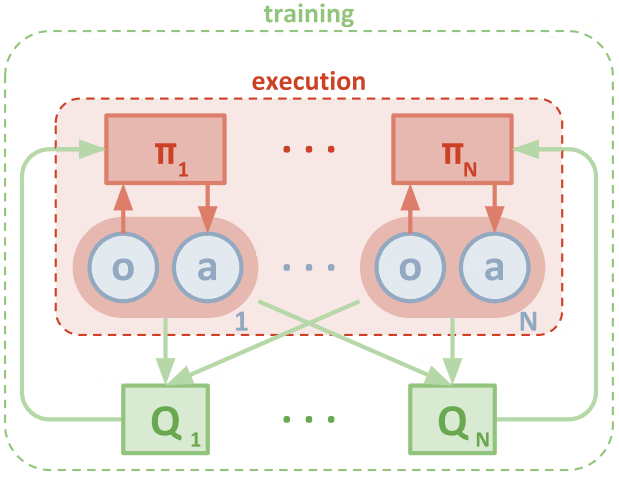
多智能体 DDPG 方法(MADDPG)
在DDPG的基础上,使用集中式训练、分布式执行的机制
伪代码

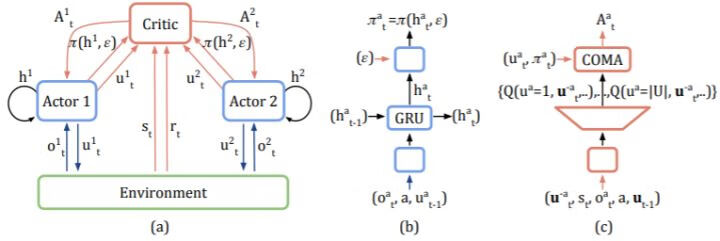
反事实多智能体策略梯度法方法(COMA)
侧重于研究每个智能体对这个共享奖励的贡献。
COMA 方法在置信分配中利用了一种反事实基线:将智能体当前的动作和默认的动作进行比较,如果当前动作能够获得的回报高于默认动作,则说明当前动作提供了好的贡献,反之则说明当前动作提供了坏的贡献;默认动作的回报,则通过当前策略的平均效果来提供(即为反事实基线)。在对某个智能体和基线进行比较的时,需要固定其他智能体的动作。
COMA 方法结合了集中式训练、分布式执行的思想:分布式的个体策略以局部观测值为输入、输出个体的动作;中心化的 critic 使用特殊的网络结构来输出优势函数值。
2.value-based 的方法
QMIX
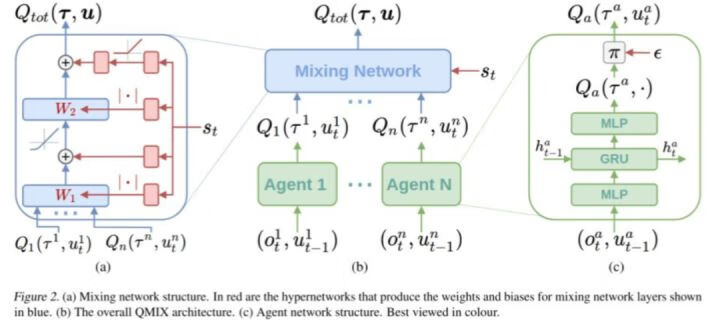
在 QMIX 方法设计的网络结构中,每个智能体都拥有一个 DRQN 网络(绿色块),该网络以个体的观测值作为输入,使用循环神经网络来保留和利用历史信息,输出个体的局部 Qi 值。
所有个体的局部 Qi 值输入混合网络模块(蓝色块),在该模块中,各层的权值是利用一个超网络(hypernetwork)以及绝对值计算产生的:绝对值计算保证了权值是非负的、使得局部 Q 值的整合满足单调性约束;利用全局状态 s 经过超网络来产生权值,能够更加充分和灵活地利用全局信息来估计联合动作的 Q 值,在一定程度上有助于全局 Q 值的学习和收敛。
结合 DQN 的思想,以 Q_tot 作为迭代更新的目标,在每次迭代中根据 Q_tot 来选择各个智能体的动作,有:
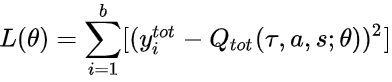
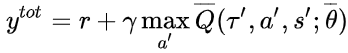
最终学习收敛到最优的 Q_tot 并推出对应的策略,即为 QMIX 方法的整个学习流程。
多智能体强化学习的应用
1.游戏应用
- 分步对抗
AlphaGo
- 实时战略
AlphaStar、OpenAI Five
2.多机器人控制
主要使用集中式学习和分布式执行的机制,在学习过程中机器人之间共享奖励、策略网络和值函数网络,通过共享的经验样本来引导相互之间达成隐式的协作机制。