
提升自己对神经网络结构理解、代码复现的能力。
4月21日
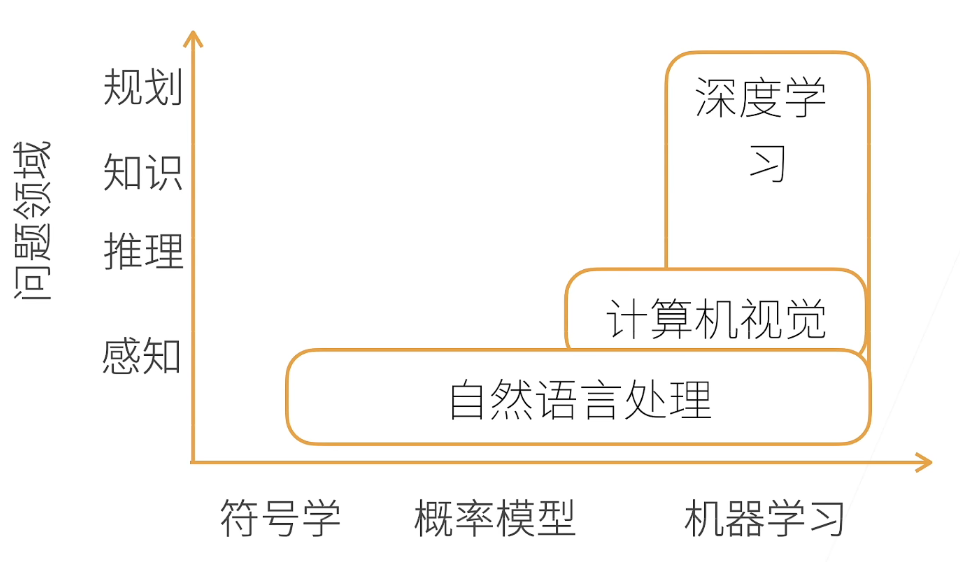
1.AI地图
2.节省内存的方法
- Y = X + Y (❌)
- Z = X + Y (✔)
- X += Y (✔)
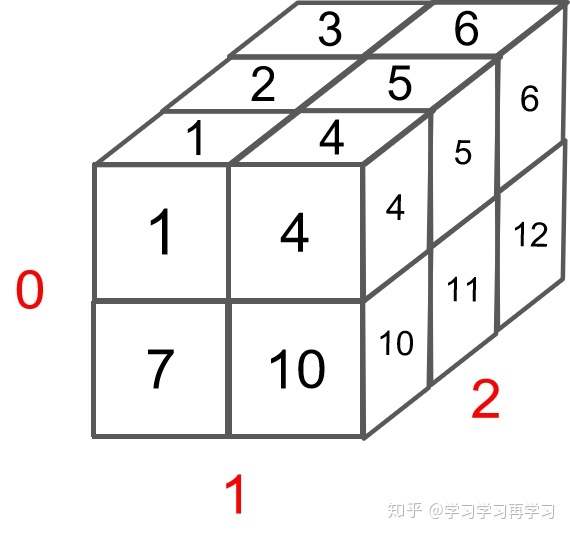
3.多维矩阵
1)对于一个3维矩阵 shape=[2, 2, 3],代码如下:
1 | x = torch.arange(12).reshape(2, 2, 3) |
可视化如下:
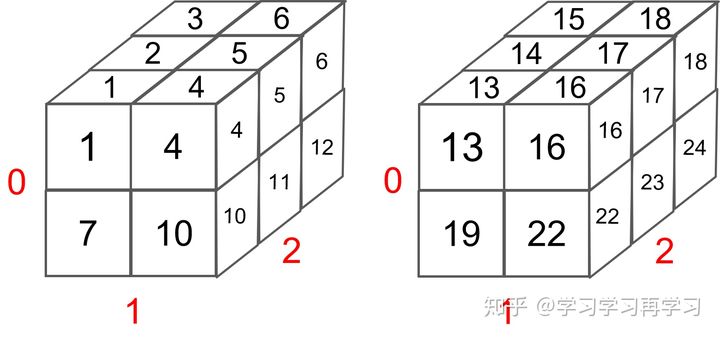
2)对于一个4维矩阵shape=[2,2,2,3],代码如下:
1 | y = torch.arange(1, 25).reshape(2, 2, 2, 3) |
可视化如下:
3)多维矩阵乘法
三维中,第一个值相等,后两维就是正常的矩阵相乘。
例:a:shape=[2, 2, 4],b:shape=[2, 4, 3]相乘,输出shape=[2, 2, 3]。
四维中,前两维是矩阵排列,相乘的话保留前的最大值。后两维就是正常的矩阵相乘。
例:a:shape=[2,1,4,5],b:shape=[1,1,5,4]相乘,输出的结果中,前两维保留的是[2,1],最终结果shape= [2,1,4,4]。
4)多维矩阵转置
shape=[2,2,4] 转置之后为 shape=[4, 2, 2]
4月22日
4.矩阵计算
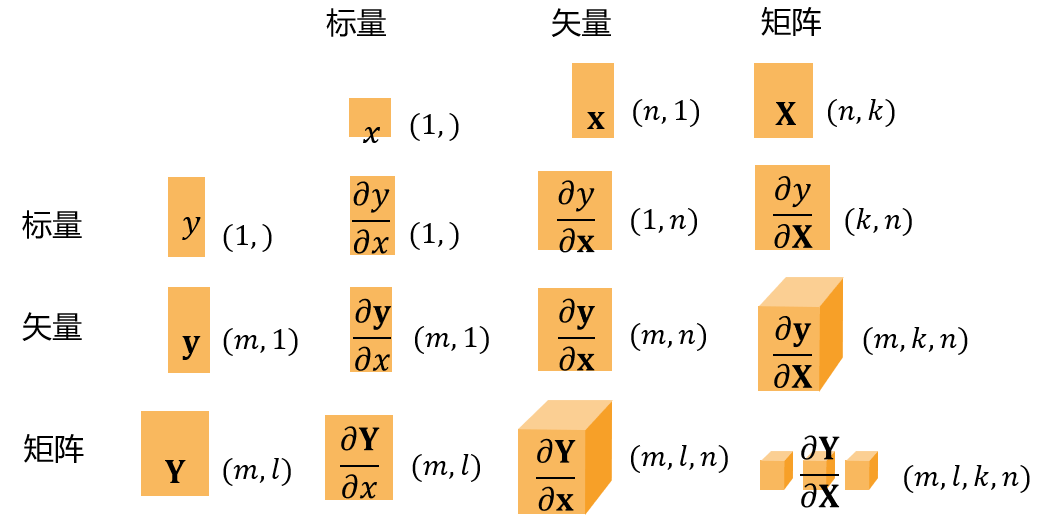
5.在深度学习中,我们“训练”模型,不断更新它们,使它们在看到越来越多的数据时变得越来越好。 通常情况下,变得更好意味着最小化一个损失函数(loss function), 即一个衡量“我们的模型有多糟糕”这个问题的分数。 最终,我们真正关心的是生成一个模型,它能够在从未见过的数据上表现良好。 但“训练”模型只能将模型与我们实际能看到的数据相拟合。 因此,我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):用模型拟合观测数据的过程;
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们生成出有效性超出用于训练的数据集本身的模型。
微分可以应用于深度学习中的优化问题,梯度是一个向量,其分量是多变量函数相对于其所有变量的偏导数。
4月23日
6.使用nn.Module实现一个线性回归模型
1 | import torch |
4月24日
7.优化算法
- 梯度下降通过不断沿着反梯度方向更新参数求解
- 小批量随机梯度下降使深度学习默认的求解算法
- 两个重要的超参数使批量大小和学习率
8.线性回归简洁实现
1)生成自定义数据集
1 | import numpy as np |
2)读取数据集
1 | def load_array(data_arrays, batch_size, is_train=True): #@save |
3)定义模型
1 | # nn是神经网络的缩写 |
4)定义损失函数
1 | loss = nn.MSELoss() # 默认情况下,它返回所有样本损失的平均值。 |
5)定义优化算法
1 | # 采用小批量随机梯度下降算法 |
6)训练
1 | num_epochs = 3 # 迭代周期 |
7)* 比较误差
1 | # 要访问参数,我们首先从net访问所需的层,然后读取该层的权重和偏置 |
9.Softmax回归
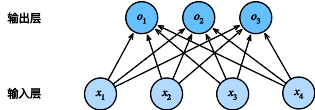
- Softmax回归是一个多类分类模型
- 使用Softmax操作子得到每个类的预测置信度
- 使用交叉熵来衡量预测和标号的区别
Softmax回归的简洁实现
1)导入Fashion-MNIST数据集
1 | import torch |
2)定义模型
1 | # PyTorch不会隐式地调整输入的形状。因此, |
3)定义损失函数
1 | loss = nn.CrossEntropyLoss(reduction='none') |
4)定义优化算法
1 | trainer = torch.optim.SGD(net.parameters(), lr=0.1) |
5)训练
1 | num_epochs = 10 |
4月25日
10.多层感知机(MLP)
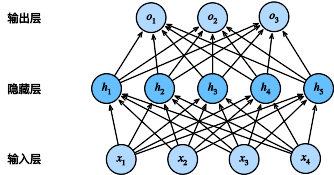
多层感知机使用隐藏层和激活函数来得到非线性模型
常用的激活函数有
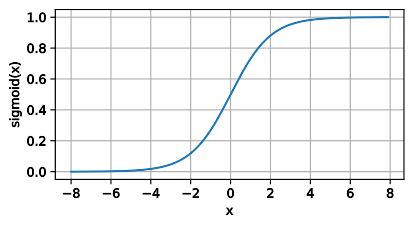
1)Sigmoid
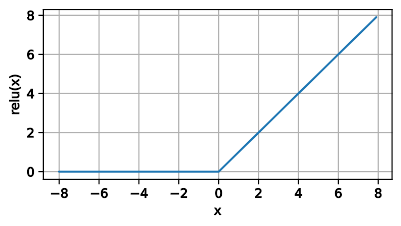
2)ReLU(使用较多)
3)tanh
使用Softmax来处理多类分类
超参数为隐藏层数,和各个隐藏层大小
多层感知机简洁实现
1)导入Fashion-MNIST数据集
1 | import torch |
2 )定义模型
1 | net = nn.Sequential(nn.Flatten(), |
3)训练
1 | num_epochs = 10 |
4月26日
11.权重衰减
- 权重衰退通过$L_2$正则项使得模型参数不会过大,从而控制模型复杂度
- 正则项权重(wd)是控制模型复杂度的超参数
原损失函数:
$L_2$正则化回归的小批量随机梯度下降:
参数更新如下:
$L_2$正则化权重衰减简洁实现:
在实例化优化器时直接通过weight_decay指定weight decay超参数。 默认情况下,PyTorch同时衰减权重和偏移。 这里我们只为权重设置了weight_decay,所以偏置参数 $b$ 不会衰减。
1 | def train_concise(wd): # 定义训练函数 |
12.Dropout(暂退法)
- 暂退法将一些输出项随机置0来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 暂退概率是控制模型复杂度的超参数
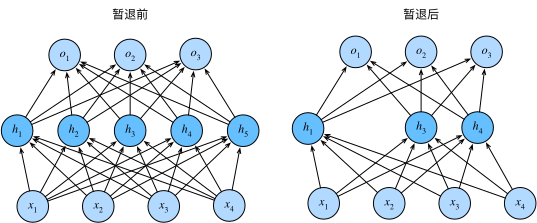
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。 换言之,每个中间活性值$h$以暂退概率$p$由随机变量$h’$替换,如下所示:
根据此模型的设计,其期望值保持不变,即$E[h’] = h$。
Dropout简洁实现:
在定义网络时,只需在每个全连接层之后添加一个Dropout层, 将暂退概率作为唯一的参数传递给它的构造函数。 在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出(相当于下一层的输入)。 在测试时,Dropout层仅传递数据。
1 | net = nn.Sequential(nn.Flatten(), |
13.合理的权重初始值(服从正态分布,均值为0,方差为一个常数)和激活函数的选取可以提升数值稳定性。
4月27日—4月28日
Kaggle竞赛——California房价预测

notebook链接:
https://www.kaggle.com/code/mikeypan0721/california-house-price-mlp
4月29日
14.卷积神经网络
1)多层感知机适合处理表格数据,但对于高维感知数据,卷积神经网络更加实用。
2)卷积神经网络(convolutional neural networks,CNN)是机器学习利用自然图像中一些已知结构的创造 性方法。
3)从全连接层——>卷积
4)平移不变性
平移不变性意味着检测对象在输入$\mathbf{X}$中的平移,应该仅导致隐藏表示$\mathbf{H}$中的平移。也就是说,$\mathsf{V}$和$\mathbf{U}$实际上不依赖于$(i, j)$的值,即$[\mathsf{V}]_{i, j, a, b} = [\mathbf{V}]_{a, b}$。并且$\mathbf{U}$是一个常数,比如$u$。因此,我们可以简化$\mathbf{H}$定义为:
这就是卷积(convolution)。我们是在使用系数$[\mathbf{V}]_{a, b}$对位置$(i, j)$附近的像素$(i+a, j+b)$进行加权得到$[\mathbf{H}]_{i, j}$。 注意,$[\mathbf{V}]_{a, b}$的系数比$[\mathsf{V}]_{i, j, a, b}$少很多,因为前者不再依赖于图像中的位置。
5)局部性
为了收集用来训练参数$[\mathbf{H}]_{i, j}$的相关信息,我们不应偏离到距$(i, j)$很远的地方。这意味着在$|a|> \Delta$或$|b| > \Delta$的范围之外,我们可以设置$[\mathbf{V}]_{a, b} = 0$。因此,我们可以将$[\mathbf{H}]_{i, j}$重写为:
这是一个卷积层(convolutional layer),而卷积神经网络是包含卷积层的一类特殊的神经网络。
6)卷积层
- 卷积层将输入和核矩阵进行交叉相关,加上偏移后得到输出
- 核矩阵和偏移是可学习的参数
- 核矩阵的大小是超参数
卷积网络代码实现:
1 | import torch |
7)填充与步幅
填充和步幅是卷积层的超参数
填充在输入周围添加额外的行/列,来控制输出形状的减少量
步幅是每次滑动核窗口时的行/列的步长,可以成倍的减少输出形状
代码实现:
1
2
3
4
5
6
7conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
5月2日
8)多输入多输出通道
- 输出通道数是卷积层的超参数
- 每个输入通道有独立的二维卷积核,所有通道结果相加得到一个输出通道结果
- 每个输出通道有独立的三维卷积核
1 | import torch |
9)池化层
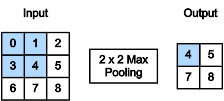
- 池化层返回窗口中最大或平均值
- 缓解卷积层位置的敏感性
- 同样有窗口的大小、填充和步幅作为超参数
1 | import torch |
5月3日
15.LeNet
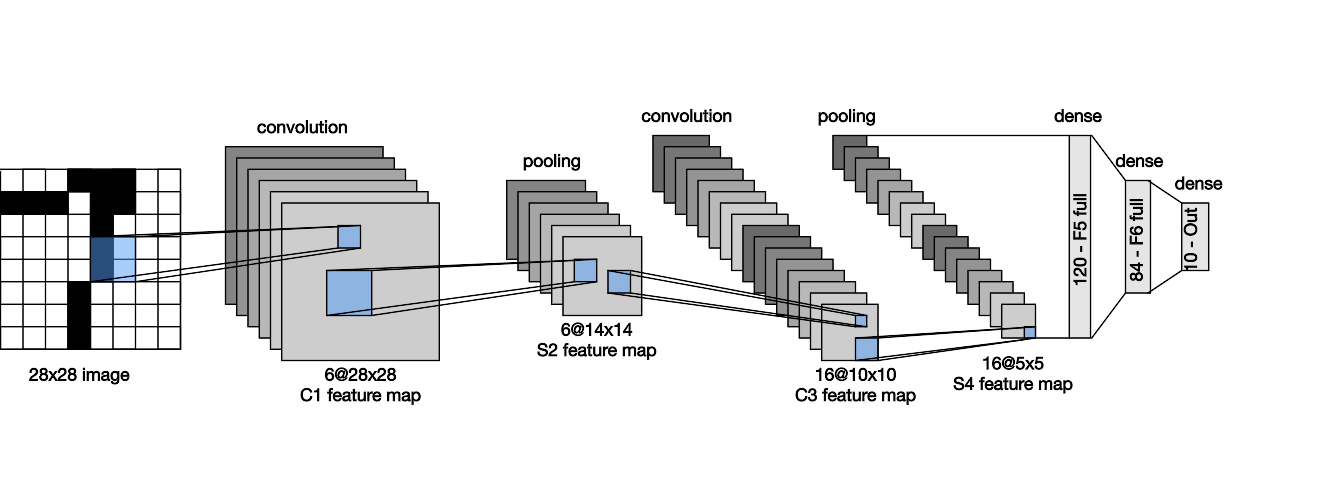

- LeNet是早期成功的神经网络
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
1 | import torch |
5月4日
16.AlexNet
- 相当于更大更深的LeNet,10x参数个数,260x计算复杂度
- 新加入了丢弃法、ReLU、最大池化层和数据增强

1 | import torch |
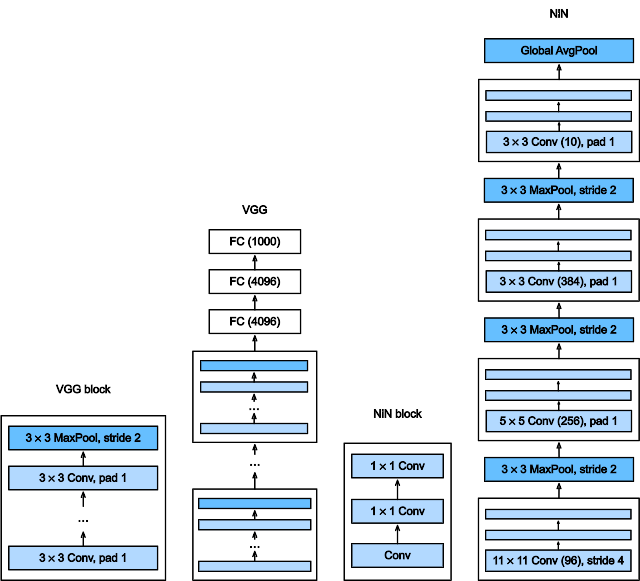
17.VGG
- VGG使用可重复的卷积块来构建深度卷积神经网络
- 不同的卷积块个数和超参数可以得到不同复杂度的变种

1 | import torch |
18.NiN
- NiN使用卷积层加两个1x1卷积层,后者的作用相当于全连接层,对每个像素增加了非线性性
- NiN使用全局平均池化层来替代VGG和AlexNet中的全连接层,优点是不容易过拟合,更少的参数个数
1 | import torch |
5月5日
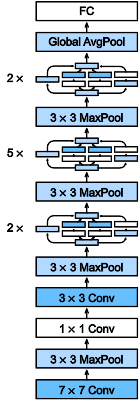
19.GoogLeNet
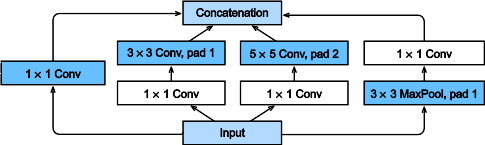
在GoogLeNet中,基本的卷积块被称为 Inception块(Inception block)。
- Inception块用4条有不同超参数的卷积层和池化层来抽取不同的信息,优点是模型参数小,计算复杂度低
- GoogLeNet使用了9个Inception块,是第一个达到上百层的网络
1 | import torch |
20.批量归一化
- 批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
- 可以加速收敛速度,但一般不改变模型精度
1 | net = nn.Sequential( |
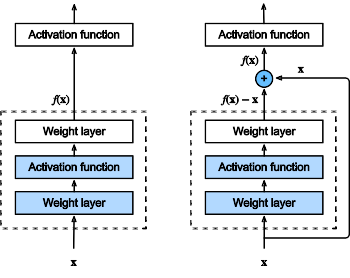
21.ResNet
- 残差块使得很深的网络更加容易训练
- 残差网络对随后的深层神经网络设计产生了深远影响,无论是卷积类网络还是全连接类网络
1 | import torch |
5月6日—5月7日
Kaggle竞赛——Classify Leaves
notebook链接:
https://www.kaggle.com/code/charlesyyun/7th-resnest-resnext-densenet-0-98840
5月8日
22.数据增强
- 数据增强通过变形数据来获得多样性从而使得模型泛化性能更好
- 常见图片增强包括翻转、切割、变色
1 | train_transform = transforms.Compose([ |
23.微调(预训练)
- 微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来完成提升精度
- 预训练模型质量很重要
- 微调通常速度更快、精度更高
1 | # ResNeSt模型 |
6月11日
从今天开始看循环神经网络
https://zh.d2l.ai/chapter_recurrent-neural-networks/index.html
6月16日
从今天开始看Transformers
https://datawhalechina.github.io/learn-nlp-with-transformers