
记录自己强化学习学习过程
4月11日
reinforcement learning算法的本质就是让agent获得状态转移矩阵
监督学习与强化学习的区别:
监督学习——Learning from teacher
强化学习——Learning from experience
Alpha Go 先进行监督学习,获得不错的效果之后再进行强化学习。
强化学习的困难之处
1)Reward delay
2)Agent的行为会对之后的情况产生影响(需要Agent具备探索能力)
Machine Learning ≈ Looking for a Function
在强化学习中,这里的Function相当于Action = Π(Observation)
强化学习方法
1)model-based(针对未来情况进行预测)
2)model-free (policy-based and/or value-based)
例:Alpha Go采用的是 policy-based+value-based+model-based
在一场游戏里面,我们把环境输出的 s 跟演员输出的行为 a ,把 s 跟 a 全部串起来, 叫做一个
Trajectory(轨迹),如下式所示。你可以计算每一个轨迹发生的概率。假设现在演员的参数已经被给定了话,就是 $\theta$。根据 $\theta$,你其实可以计算某一个轨迹发生的概率,你可以计算某一个回合里面发生这样子状况的概率。
你可以根据 $\theta$ 算出某一个轨迹 $\tau$ 出现的概率,接下来计算这个 $\tau$ 的总奖励是多少。总奖励使用这个 $\tau$ 出现的概率进行加权,对所有的 $\tau$ 进行求和,就是期望值。给定一个参数,你会得到的期望值。
计算梯度
强化学习的一下Tips
1)添加baseline
2)给每个动作合适的分数
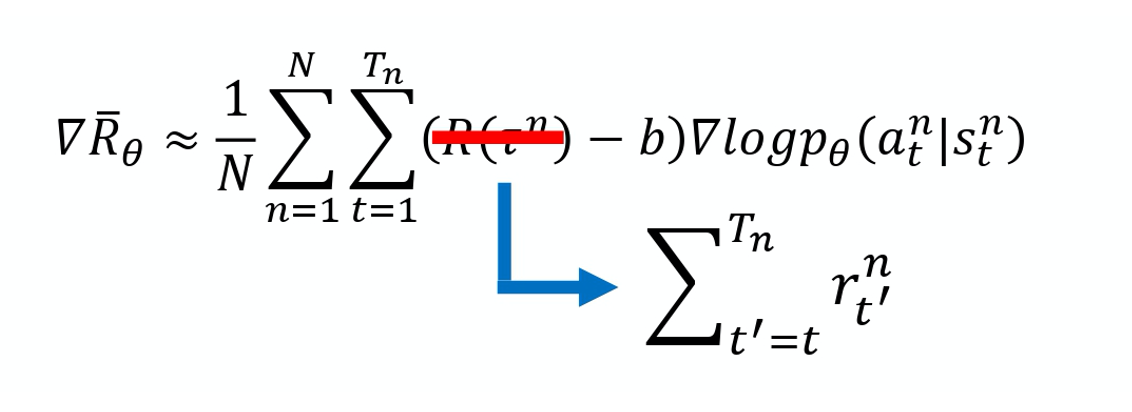
本来的权重是整场游戏的奖励的总和,现在改成从某个时间 t 开始,假设这个动作是在 t 这个时间点所执行 的,从 t 这个时间点一直到游戏结束所有奖励的总和,才真的代表这个动作是好的还是不好的。
3)折扣回报
4)优势函数
把 R-b 这一项合起来,我们统称为优势函数(advantage function), 用 A 来代表优势函数。优势函数取决于 s 和 a,我们就是要计算的是在某一个状态 s 采取某一个动作 a 的时候,优势函数有多大。

优势函数的意义在于,假设我们在某一个状态 $s_t$ 执行某一个动作 $a_t$,相较于其他可能的动作,它有多好。它在意的不是一个绝对的好,而是相对的好,即相对优势(relative advantage)。因为会减掉一个 b,减掉一个 基线, 所以这个东西是相对的好,不是绝对的好。 $A^{\theta}\left(s_{t}, a_{t}\right)$ 通常可以是由一个网络估计出来的,这个网络叫做 critic。
4月12日
Behavior Cloning的缺点在于无法告诉Machine哪些是重要的,哪些是不重要的。
Two Learning Scenarios:
1)强化学习
2)Learning by demonstration
Actor-Critic算法:
1)Training an Actor
2)Training a Critic
3)Actor + Critic
一个 Critic 无法决定 Action,Critic 的作用是评估一个 actor Π 好不好。(给出最终奖励的期望)
评论家(Critic)是指值函数 $V^{\pi}(s)$,对当前策略的值函数进行估计,即评估演员的好坏。
4月13日
DQN算法学习
1)有一种 Critic 是
state value function(状态价值函数)。评论家的输出是跟演员有关的,状态的价值其实取 决于你的演员,当演员变的时候,状态价值函数的输出其实也是会跟着改变的。2)衡量状态价值函数 $V^{\pi}(s)$ 的两种方法:
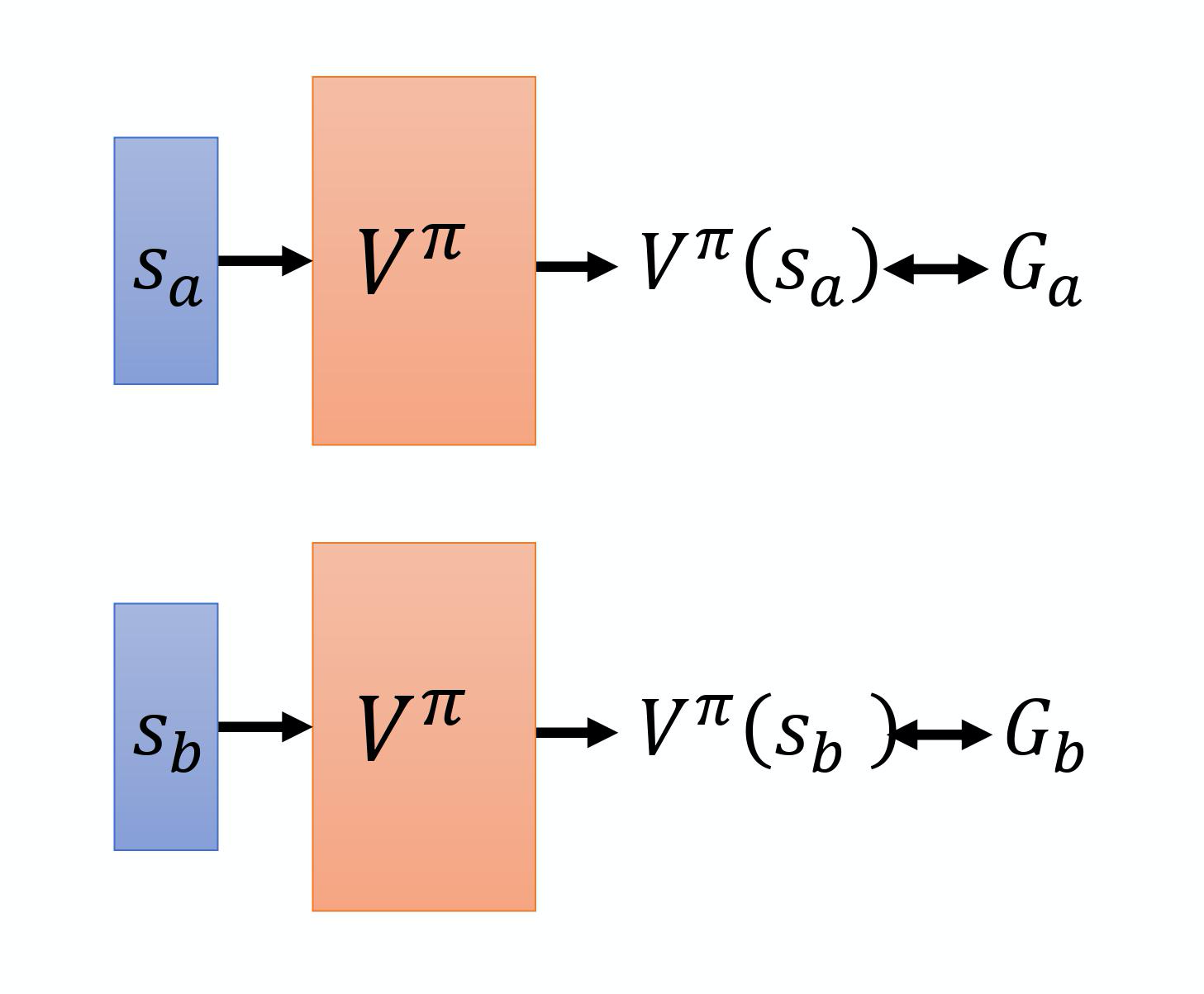
(1)Monte-Carlo(MC)-based
在训练的时候, 它就是一个回归问题。网络的输出就是一个值,你希望在输入 $s_a$ 的时候,输出 的值跟 $G_a$ 越近越好,输入 $s_b$ 的时候,输出的值跟 $G_b$ 越近越好。
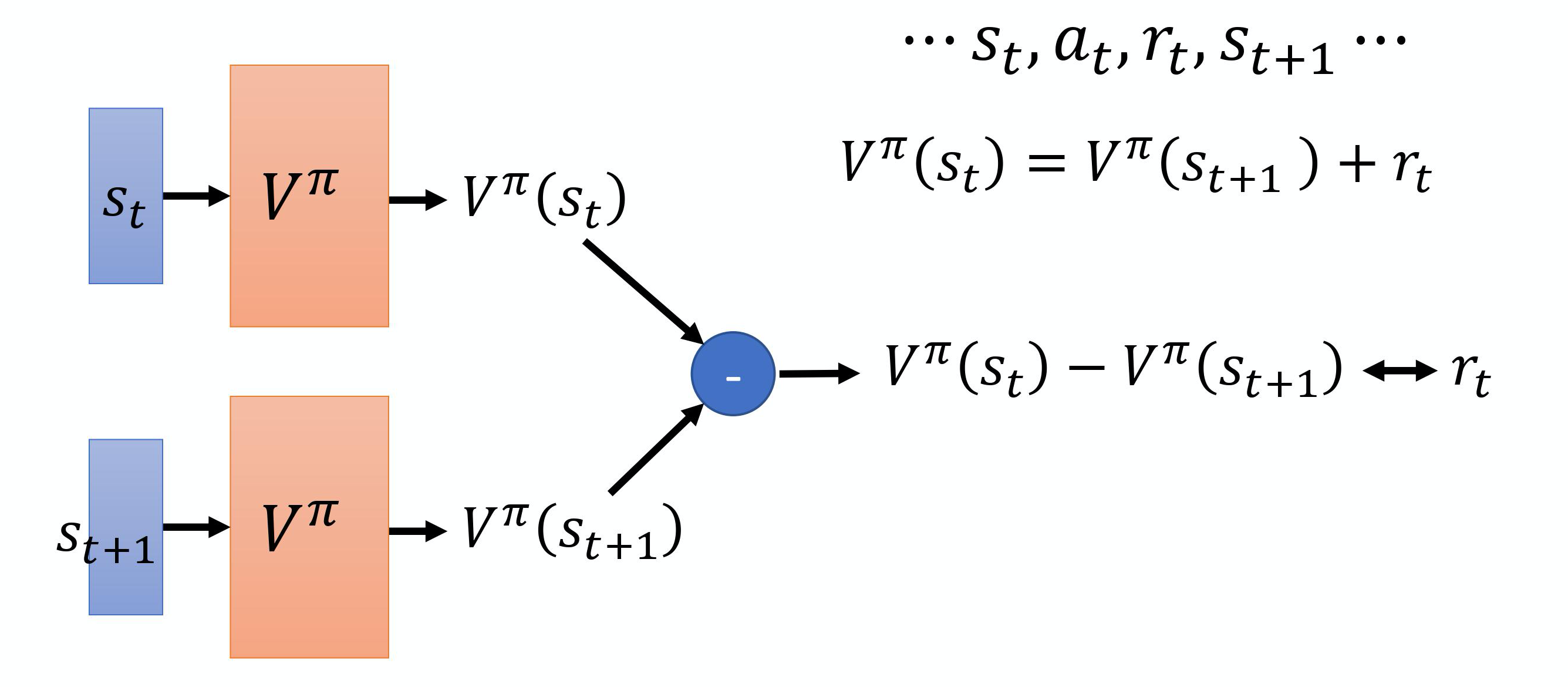
(2)Temporal-difference(时序差分)
TD-based 的方法不需要把游戏玩到底,只要在游戏的某一个情况,某一个状态 $s_t$ 的时候,采取动 作 $a_t$ 得到奖励$r_t$ ,跳到状态 $s_{t+1}$,就可以使用 TD 的方法。
3)另一种 Ctitic 是 Q-function,也叫
state-action value function(状态-动作价值函数)。状态-动作价值 函数的输入是一个状态、动作对,它的意思是说,在某一个状态采取某一个动作,假设我们都使用演员 $\pi$ ,得到的累积奖励的期望值有多大。 推导可得:
因此:
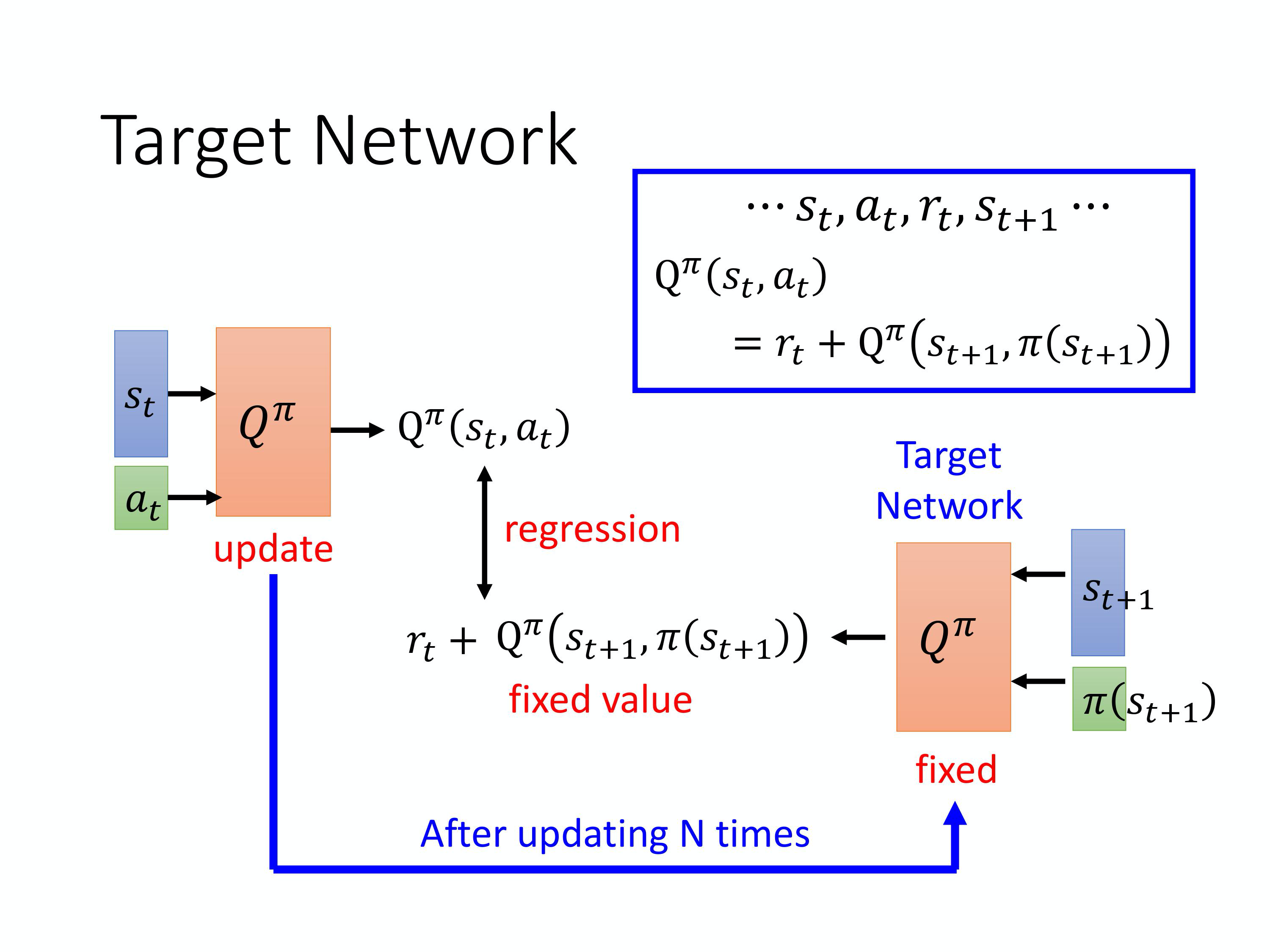
4)DQN中用到的一些Tips:
(1)目标网络
(2)探索(Exploration)

(3)Experience Replay(经验回放)
构建一个 Replay Buffer,用先有某一个策略 $\pi$ 去跟环境做互动,然后它会去收集数据,并利用收 集到的数据更新参数。
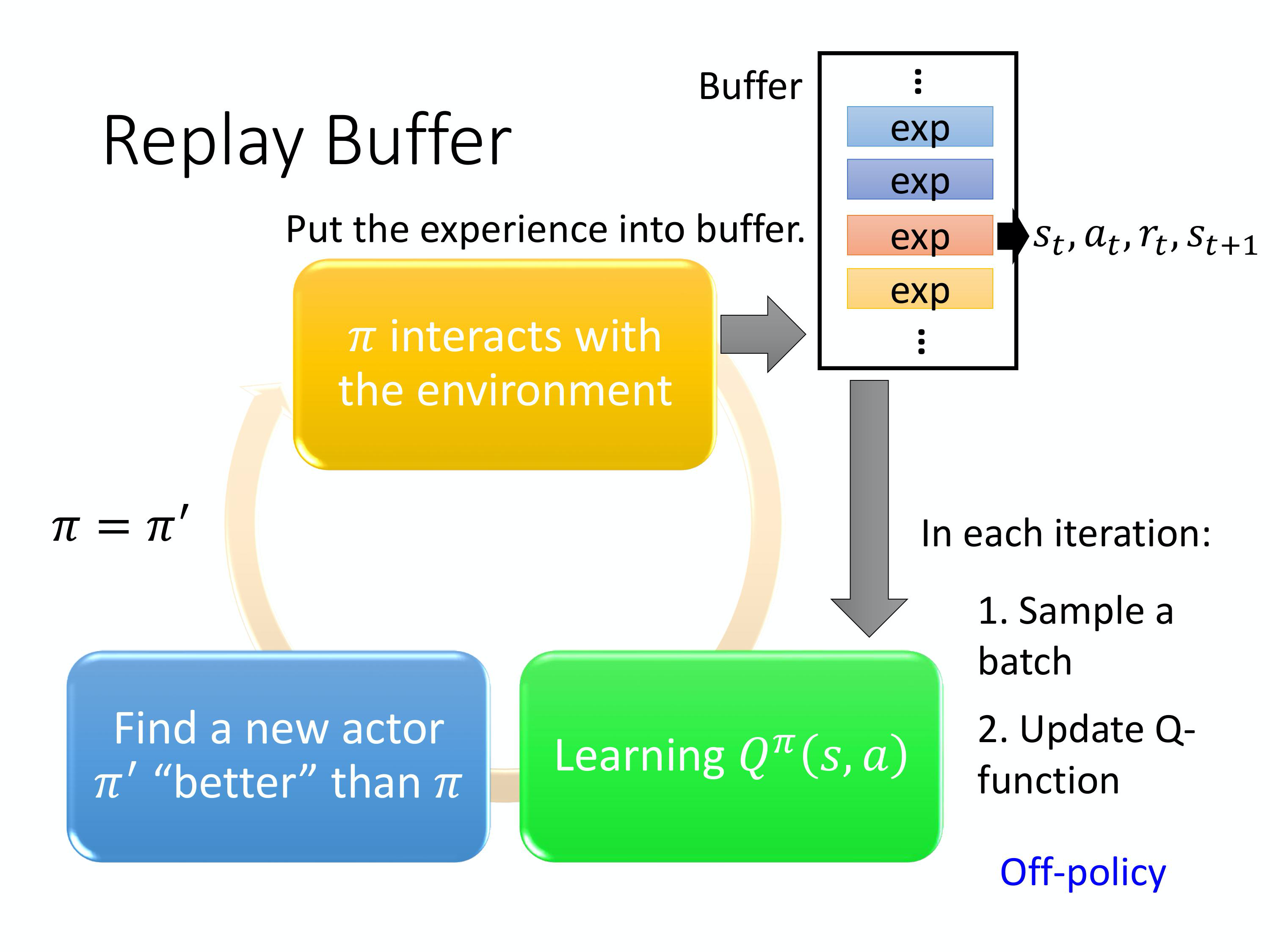
5)DQN算法总结

4月14日
DQN进阶技巧
1)Double DQN

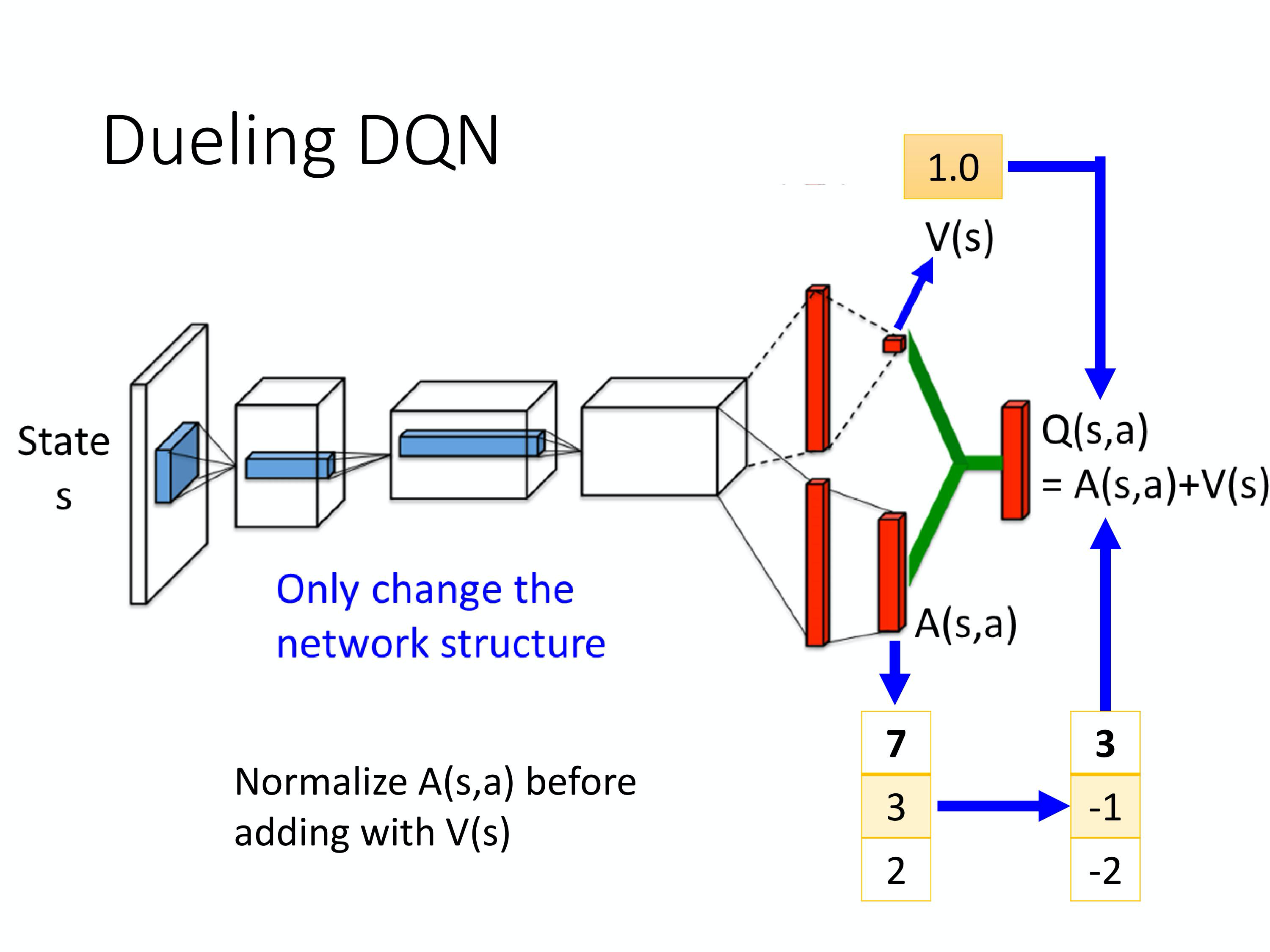
2)Dueling DQN
3)Prioritized Experience Replay

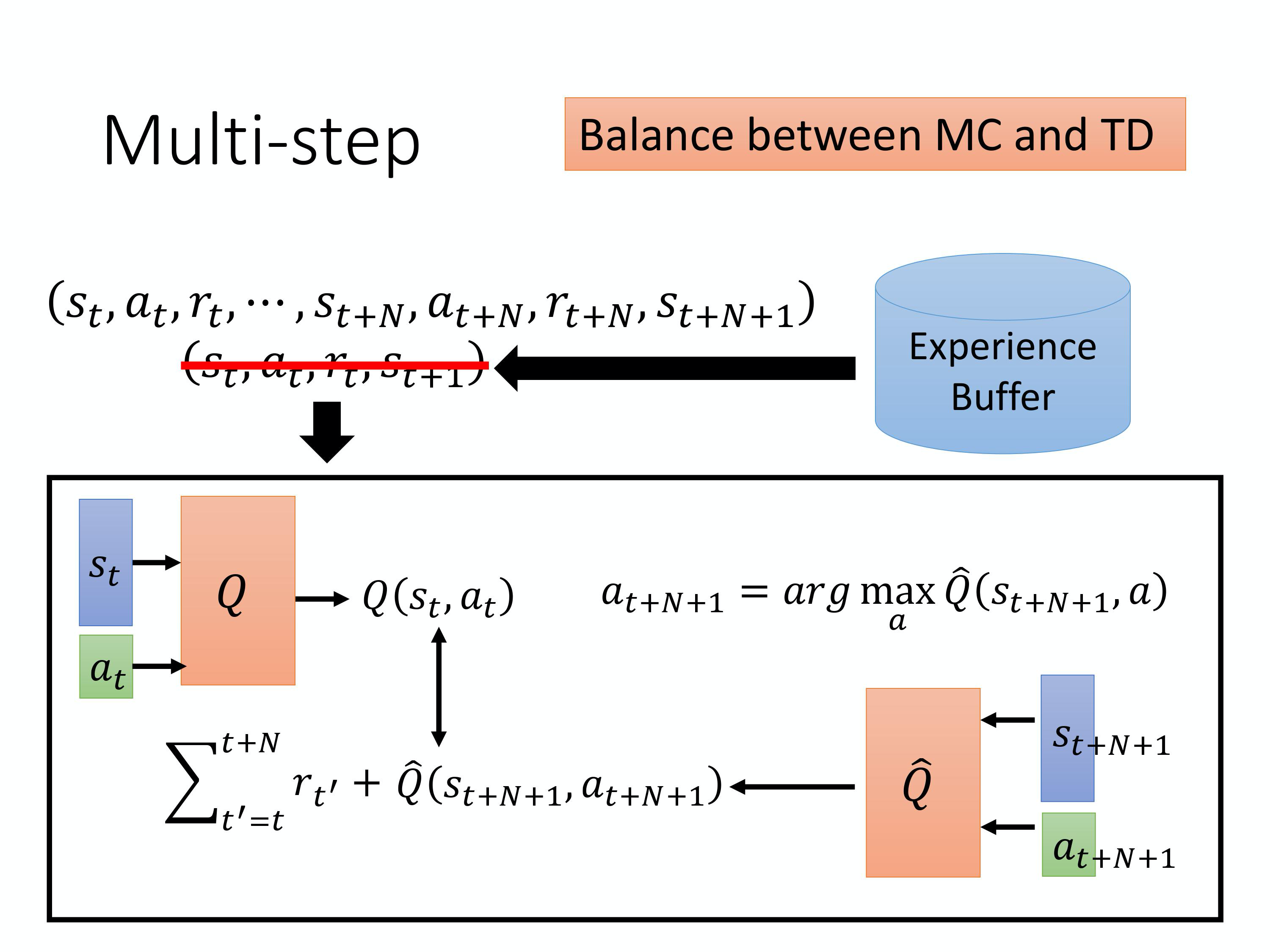
4)Balance between MC and TD
5)Noisy Net

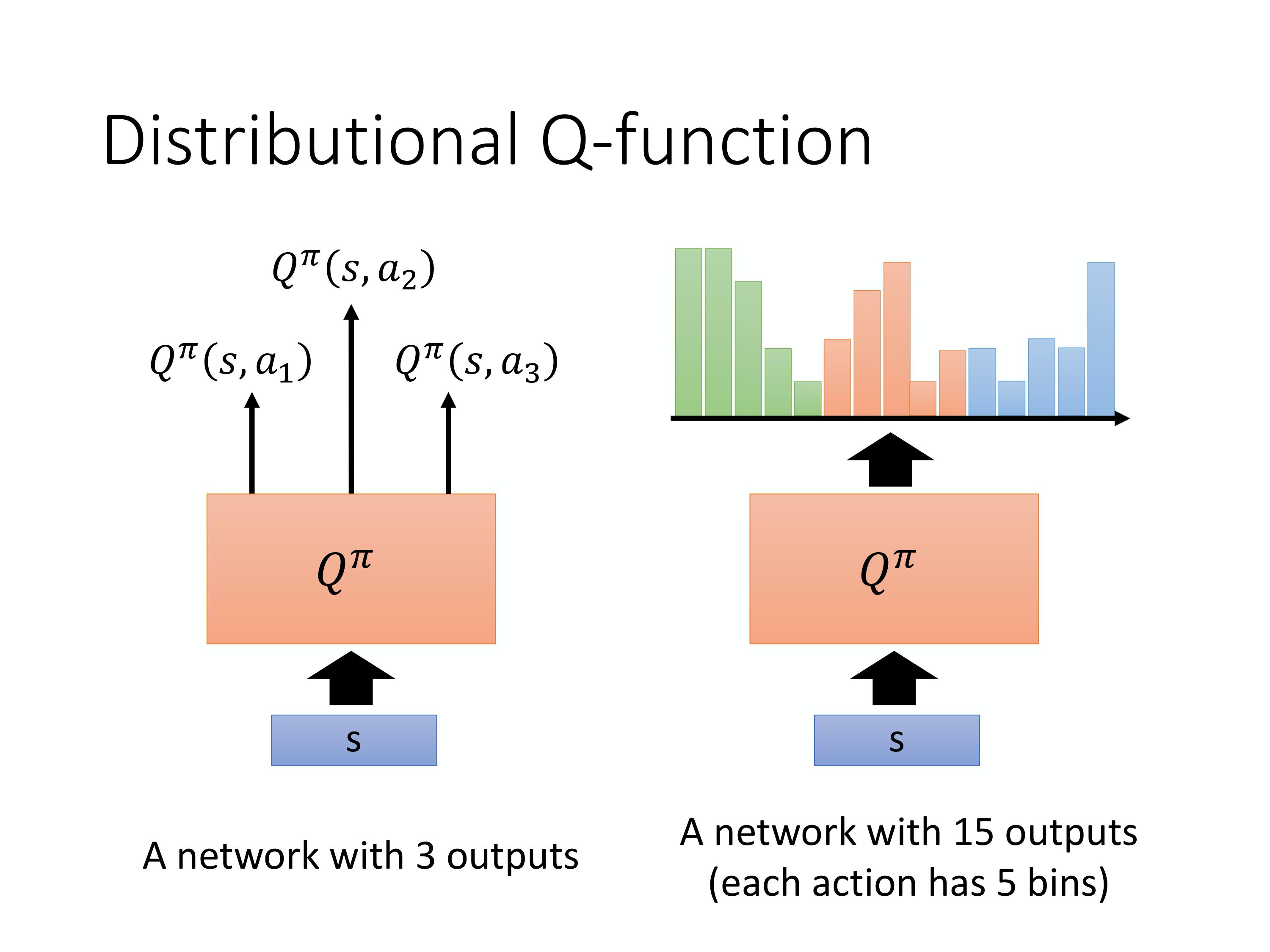
6)Distributional Q-function
7)Rainbow
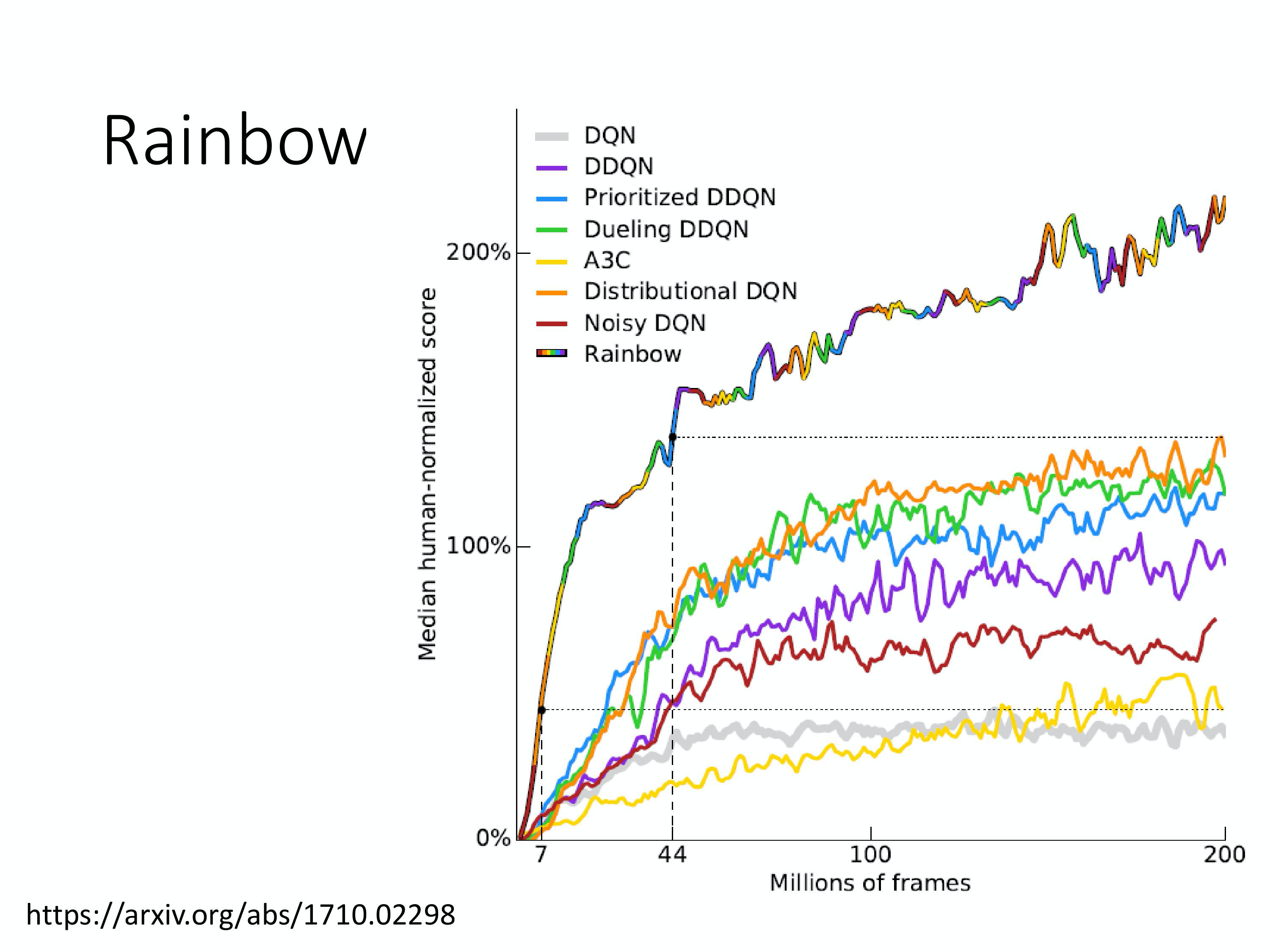
4月15日
实现 DQN算法 玩 MountainCar-v0,并能够保存模型和加载模型。
4月16日
PPO算法学习
1)on-policy 和 off-policy
如果要学习的 agent 跟和环境互动的 agent 是同一个的话, 这个叫做on-policy(同策略)。
如果要学习的 agent 跟和环境互动的 agent 不是同一个的话, 那这个叫做off-policy(异策略)。
2)policy gradient 是一个 on-policy 的算法。
3)近端策略优化(Proximal Policy Optimization,简称 PPO) 是 policy gradient 的一个变形,它是现 在 OpenAI 默认的强化学习算法。
4)重要性采样(Importance Sampling,IS)
期望值 $E_{x \sim p}[f(x)]$ 其实就是 $\int f(x) p(x) dx$,对其做如下的变换:
就可以写成对 q 里面所采样出来的 $x$ 取期望值,其中 $\frac{p(x)}{q(x)}$ 为重要性权重(importance weight) 。
在实现上,p 和 q 不能差太多。因为方差不同:
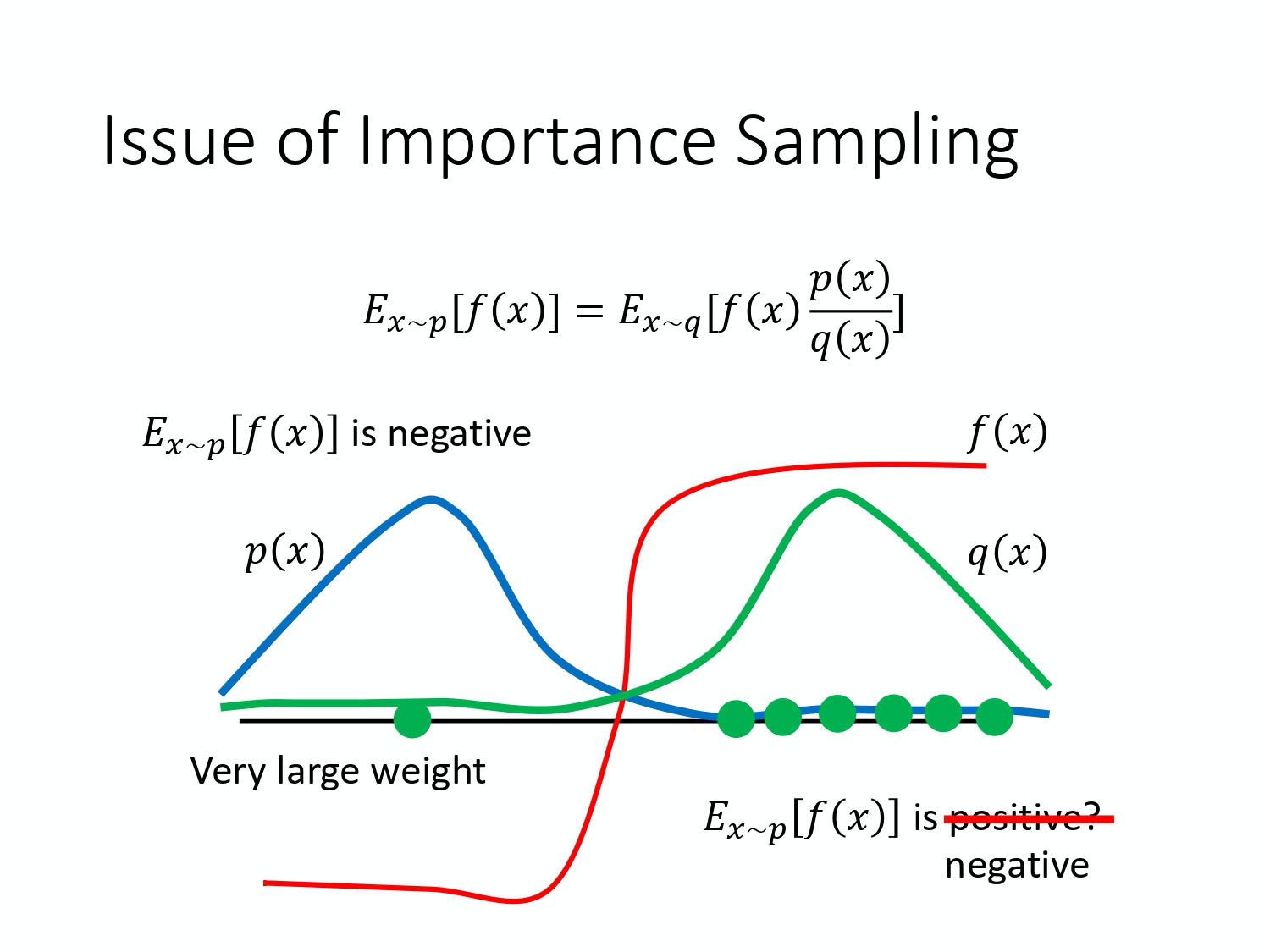
5)on-policy —-> off-policy

现在我们得到一个新的目标函数:
6)PPO 是 on-policy 的算法,在 PPO 中 $\theta’$ 是 $\theta_{\text{old}}$,即 behavior policy 也是 $\theta$。如果 $p_{\theta}\left(a_{t} | s_{t}\right)$ 跟 $p_{\theta’}\left(a_{t} | s_{t}\right)$ 这两个分布差太多的话,重要性采样的结果就会不好。这也是PPO要解决的问题。
7)在做 PPO 的时候,所谓的 KL 散度并不是参数的距离,而是动作的距离。
8)PPO-Penalty
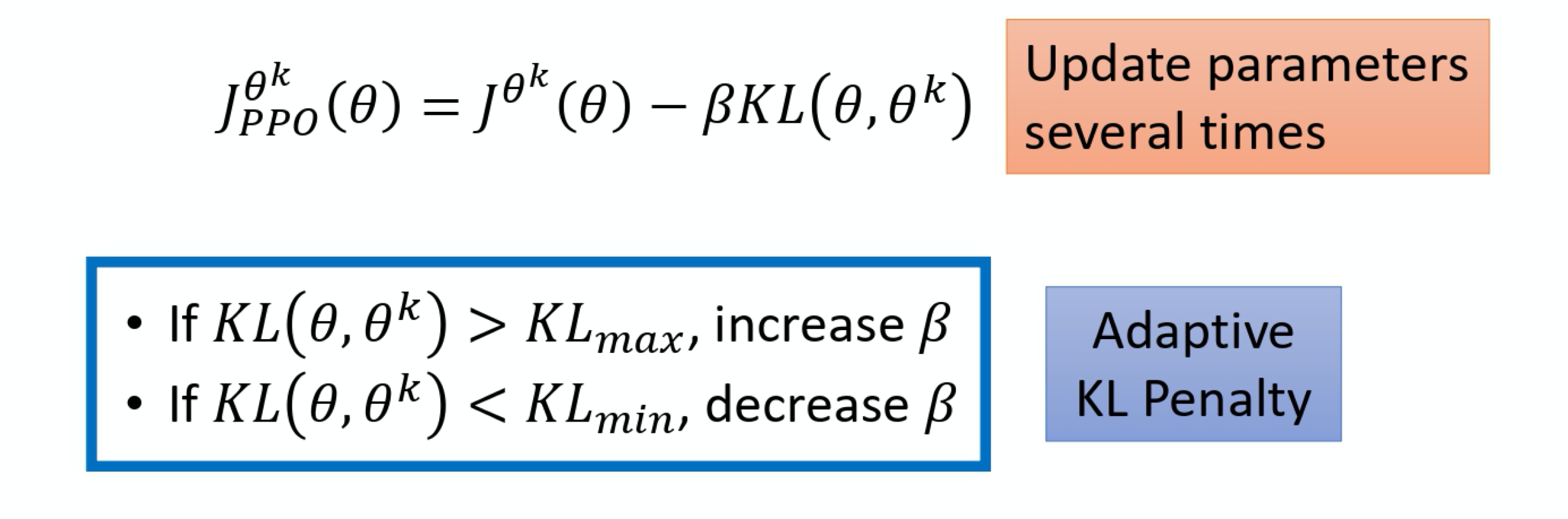
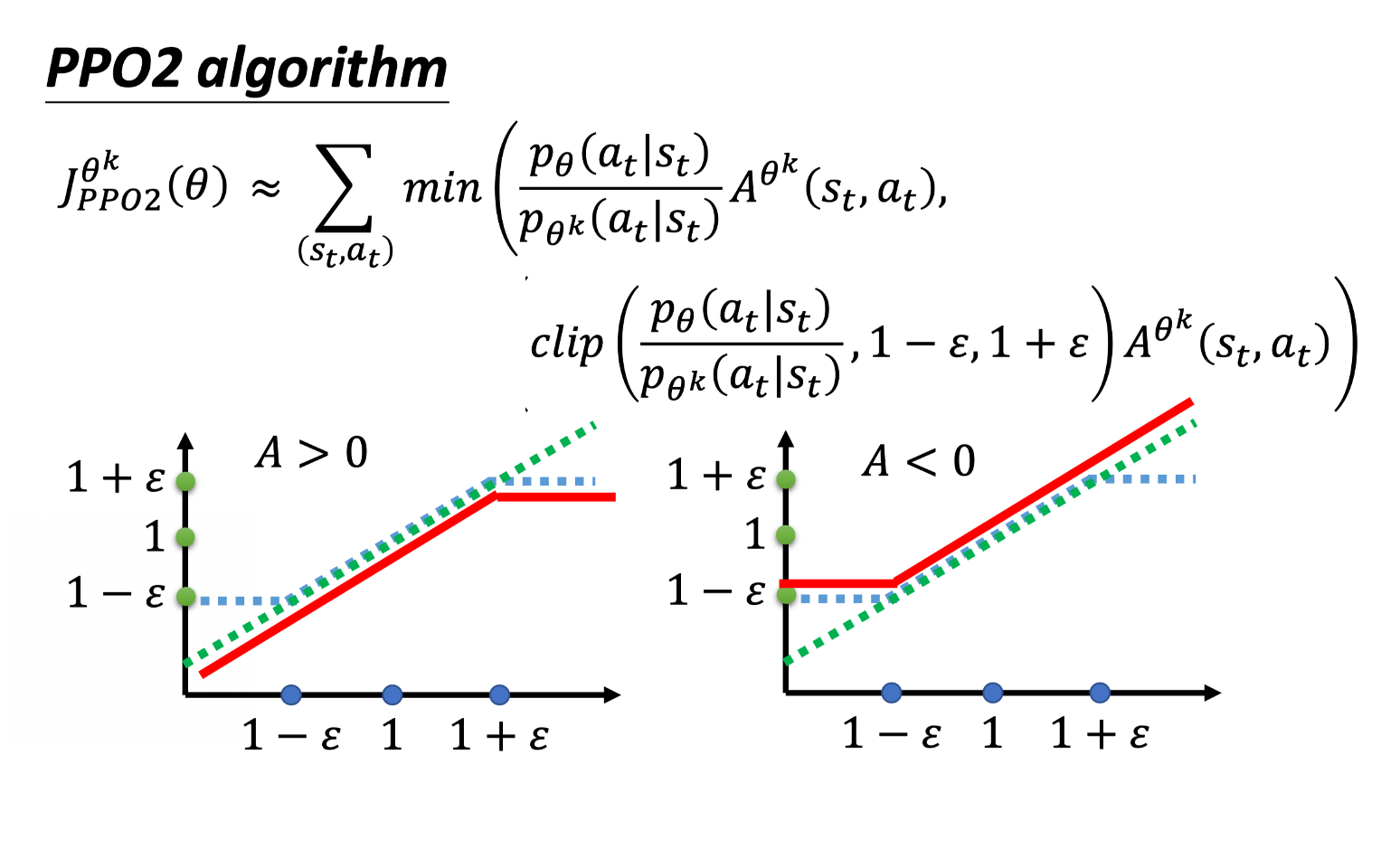
9)PPO-Clip
Min 这个操作符(operator)做的事情是第一项跟第二项里面选比较小的那个。
第二项前面有个 clip 函数,clip 函数的意思是说,
- 在括号里面有三项,如果第一项小于第二项的话,那就输出 $1-\varepsilon$ 。
- 第一项如果大于第三项的话,那就输出 $1+\varepsilon$。
$\varepsilon$ 是一个超参数,你要 tune 的,你可以设成 0.1 或 设 0.2 。
4月17日
实现 PPO算法 玩 Pendulum-v1。

4月18日
Actor-Critic算法学习
1)
演员-评论家算法(Actor-Critic Algorithm)是一种结合策略梯度和时序差分学习的强化学习方法,其中:- 演员(Actor)是指策略函数 $\pi_{\theta}(a|s)$,即学习一个策略来得到尽量高的回报。
- 评论家(Critic)是指值函数 $V^{\pi}(s)$,对当前策略的值函数进行估计,即评估演员的好坏。
- 借助于值函数,演员-评论家算法可以进行单步更新参数,不需要等到回合结束才进行更新。
2)A2C——Advantage Actor-Critic
A3C——Asynchronous Advantage Actor-Critic
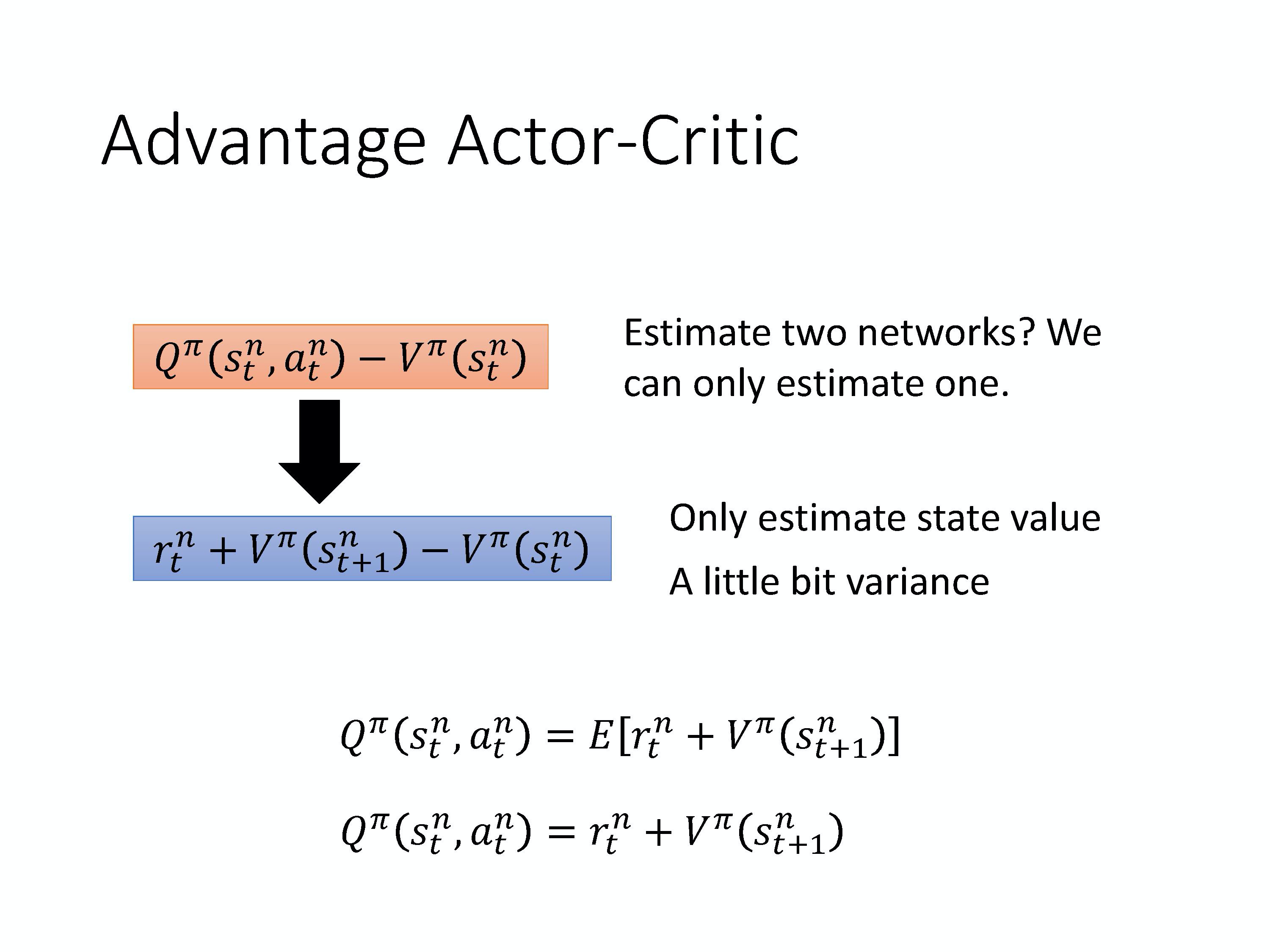
3)Q-Learning 使基于价值的方法(value-based),有两种 critics。
- 第一种 critic 是 $V^{\pi}(s)$,它的意思是说,假设 actor 是 $\pi$,拿 $\pi$ 去跟环境做互动,当我们看到状态 s 的时候,接下来累积奖励 的期望值有多少。
- 还有一个 critic 是 $Q^{\pi}(s,a)$。$Q^{\pi}(s,a)$ 把 s 跟 a 当作输入,它的意思是说,在状态 s 采取动作 a,接下来都用 actor $\pi$ 来跟环境进行互动,累积奖励的期望值是多少。
- $V^{\pi}$ 输入 s,输出一个标量。
- $Q^{\pi}$ 输入 s,然后它会给每一个 a 都分配一个 Q value。
- 你可以用 TD 或 MC 来估计。用 TD 比较稳,用 MC 比较精确。
4)A2C (Advantage Actor-Critic)
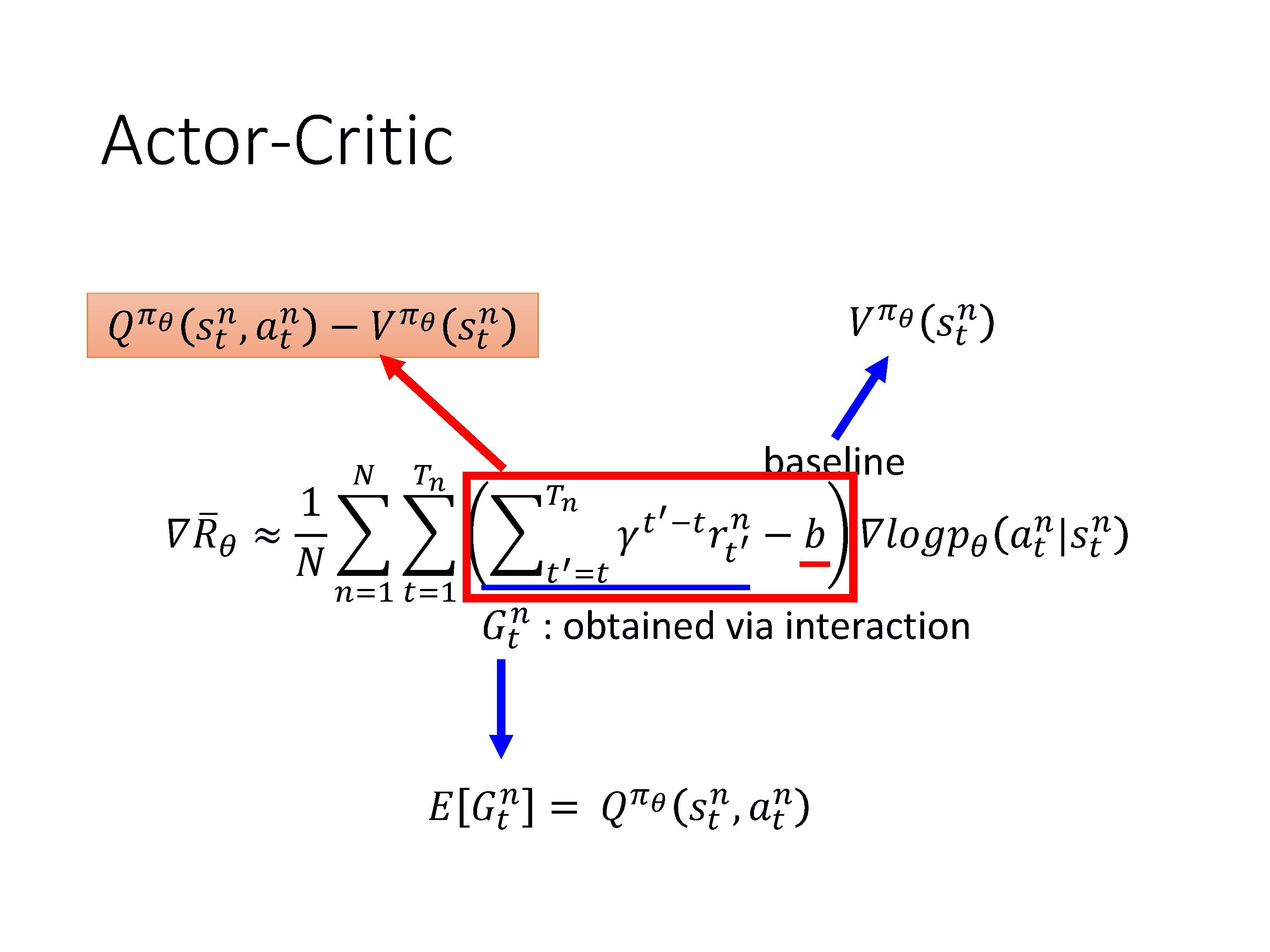
A2C算法流程:
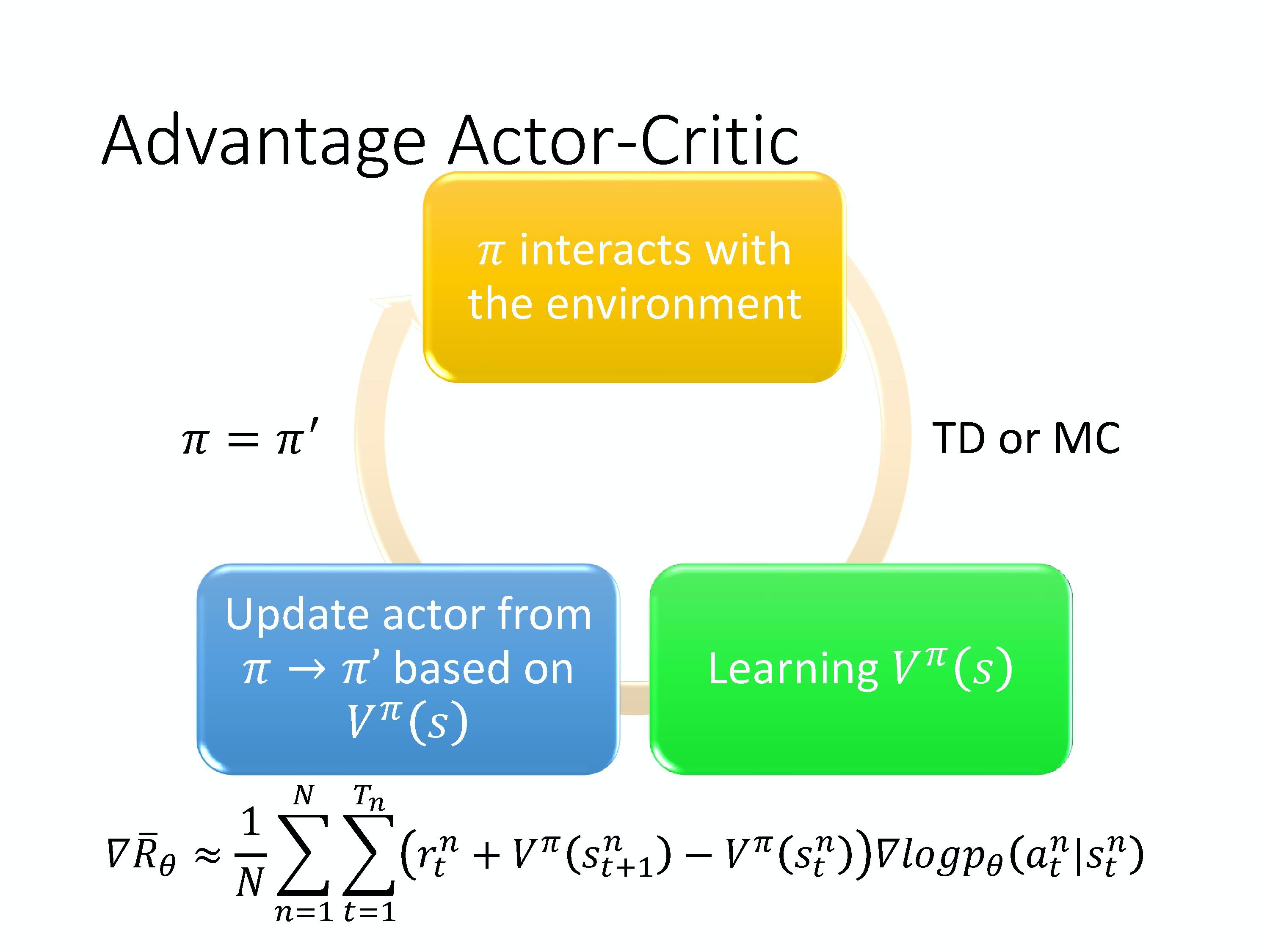
用到的Tips:
(1)actor (policy) 和 critic (V function) 的输入都是 s,所以它们前面几个层(layer)是可以共享的。
(2)仍然需要探索(exploration)的机制。
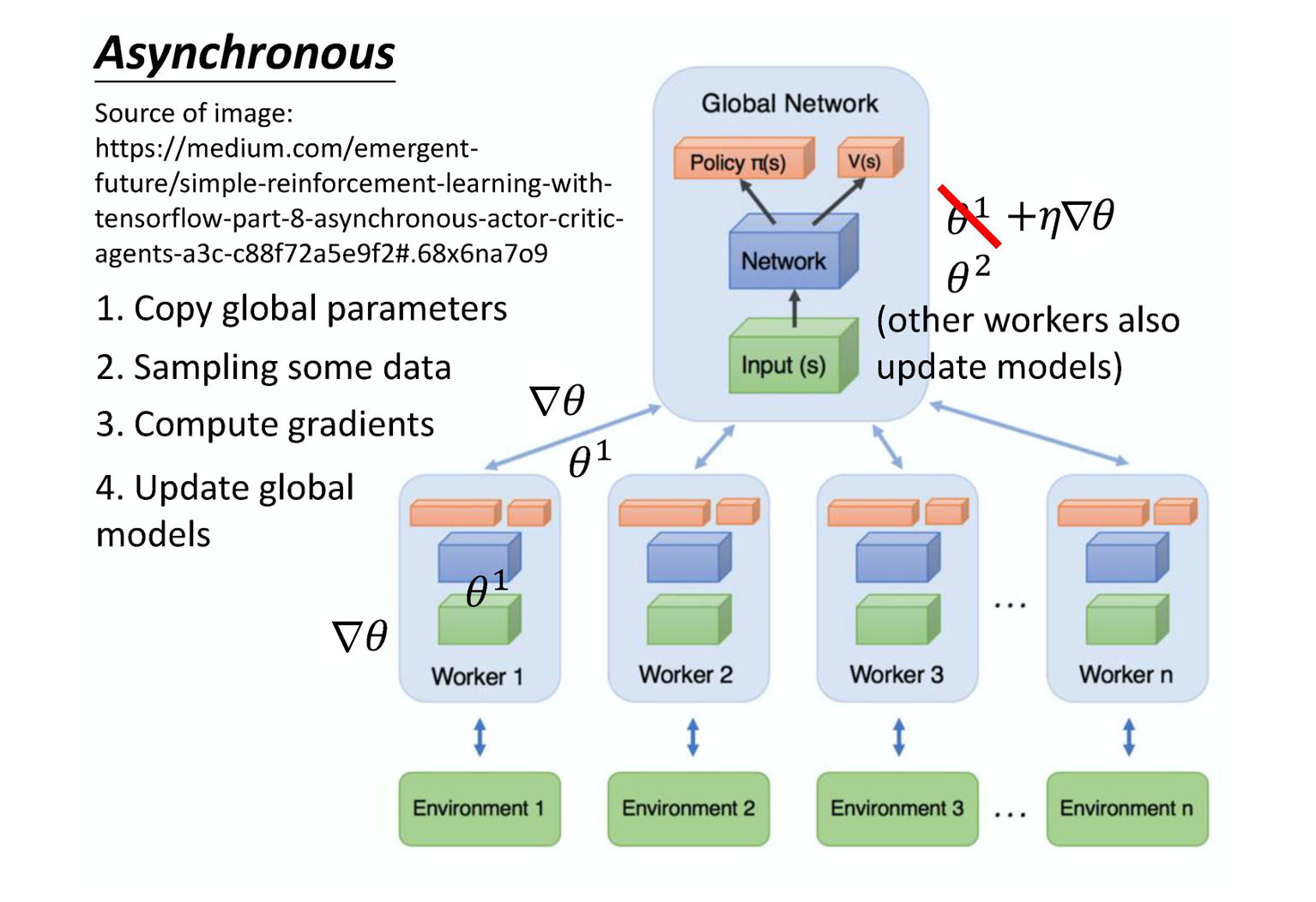
5)A3C (Asynchronous(异步的) Advantage Actor-Critic)
A3C 这个方法就是同时开很多个 worker,那每一个 worker 其实就是一个影分身。那最后这些影分身会把所有的经验,通通集合在一起。
6)Pathwise Derivative Policy Gradient
在Q-Learning算法基础上进行改变。


7) GAN 跟 Actor-Critic 的方法非常类似。
4月19日
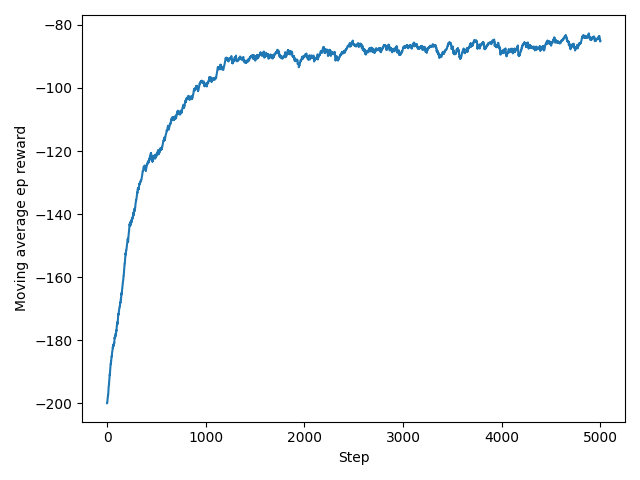
实现 A3C算法 玩 Acrobot-v1,并利用matplotlib绘制期望奖励曲线。

19.DDPG算法学习
1)随机性策略与确定性策略
- 对随机性的策略来说,输入某一个状态 s,采取某一个 action 的可能性并不是百分之百,而是有一个概率 P 的,就好像抽奖一样,根据概率随机抽取一个动作。
- 而对于确定性的策略来说,它没有概率的影响。当神经网络的参数固定下来了之后,输入同样的 state,必然输出同样的 action,这就是确定性的策略。
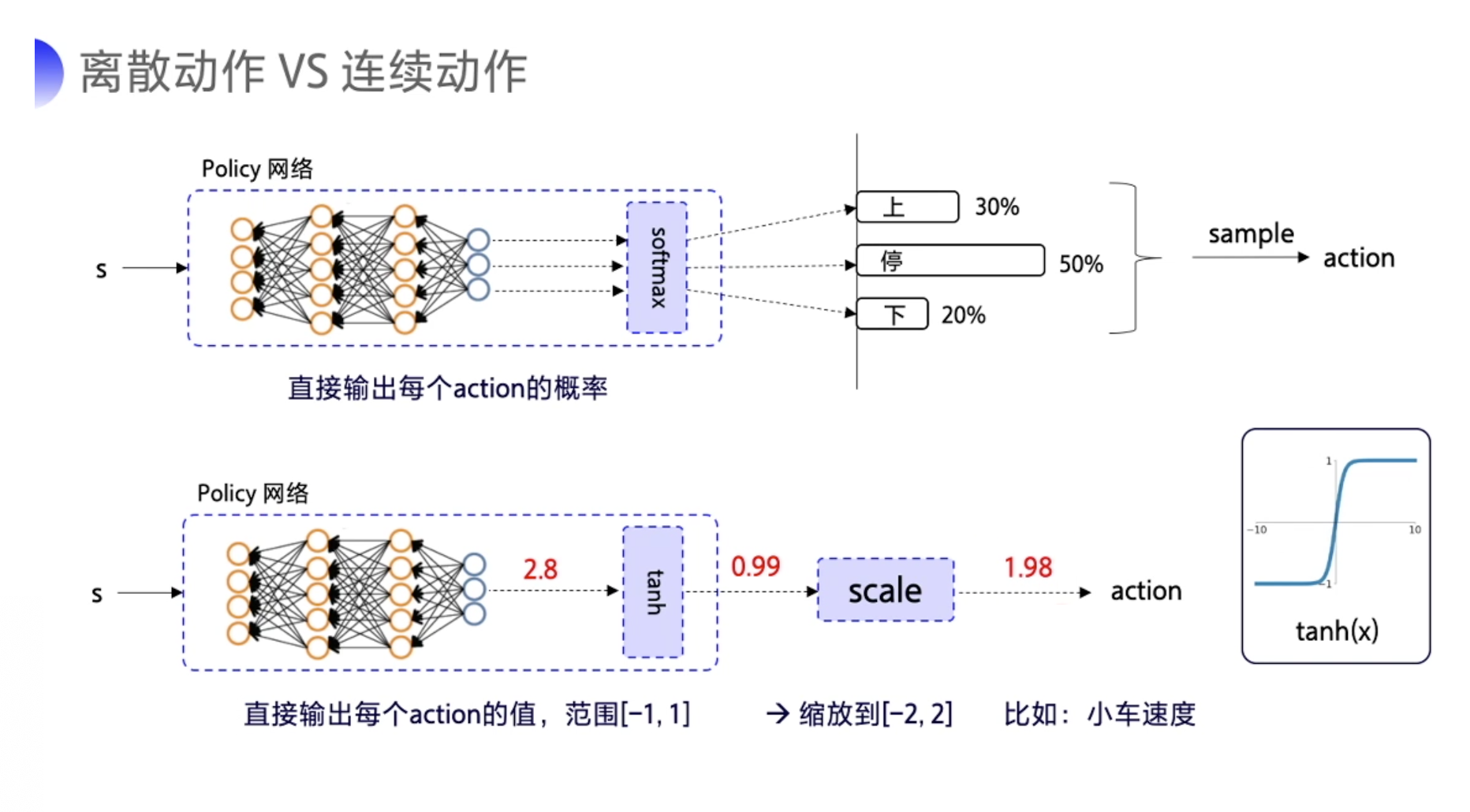
*tanh 的图像的像右边这样子,它的作用就是把输出限制到 [-1,1] 之间。
2)DDPG 的特点可以从它的名字(Deep Deterministic Policy Gradient)当中拆解出来,拆解成 Deep、Deterministic 和 Policy Gradient。
- Deep 是因为用了神经网络;
- Deterministic 表示 DDPG 输出的是一个确定性的动作,可以用于连续动作的一个环境;
- Policy Gradient 代表的是它用到的是策略网络。REINFORCE 算法每隔一个 episode 就更新一次,但 DDPG 网络是每个 step 都会更新一次 policy 网络,也就是说它是一个单步更新的 policy 网络。
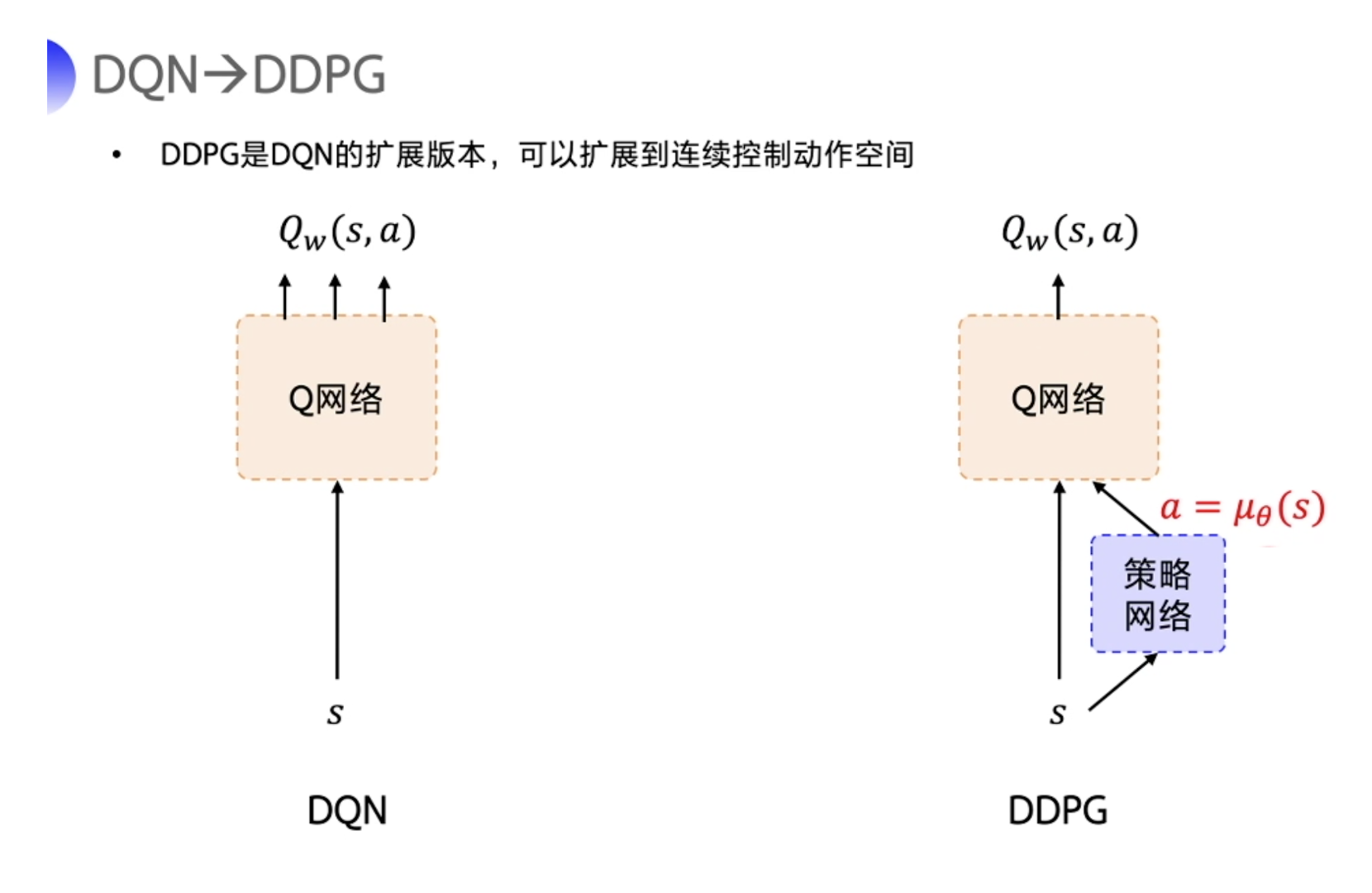
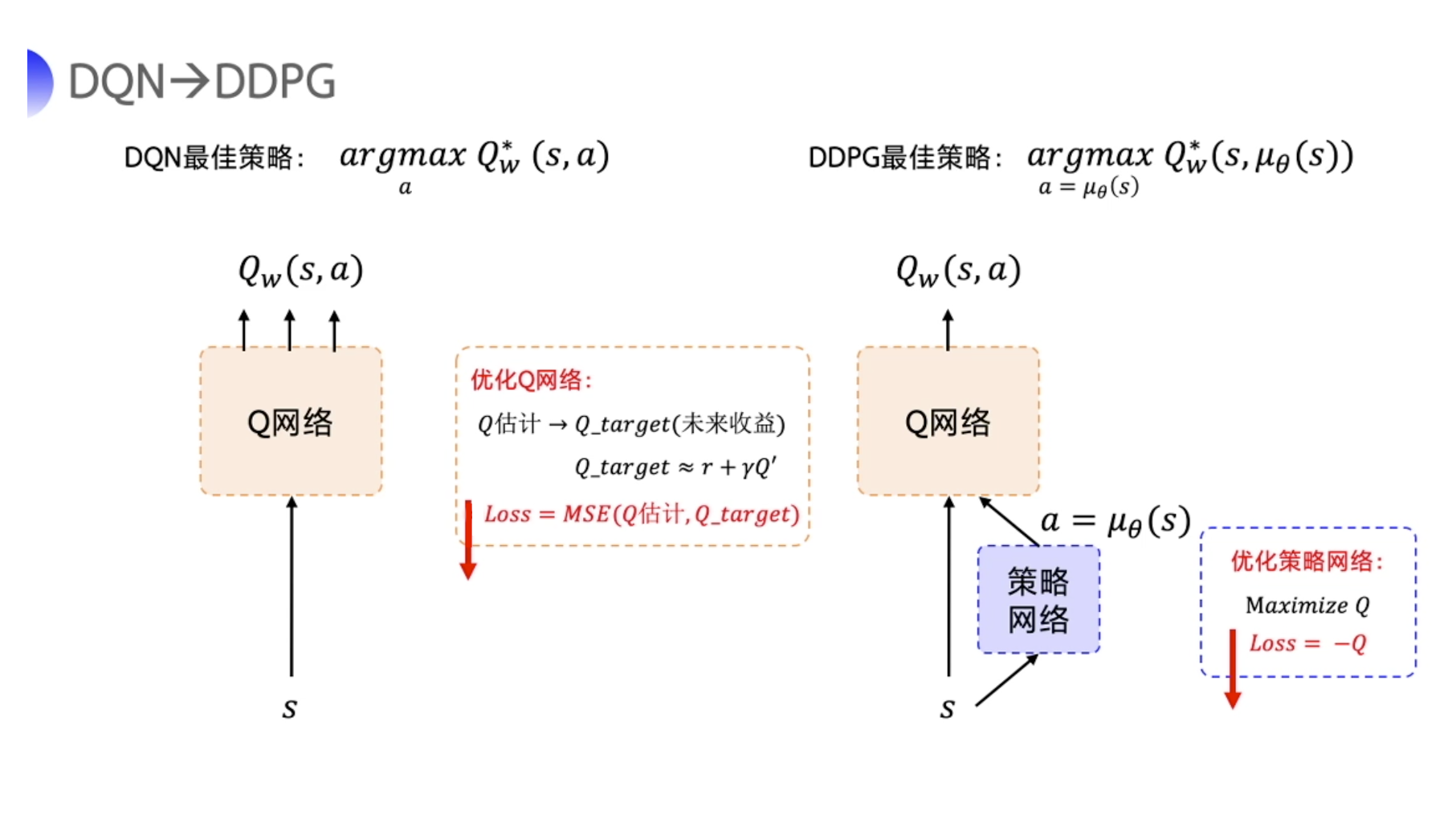
提出 DDPG 是为了让 DQN 可以扩展到连续的动作空间。
- DDPG 直接在 DQN 基础上加了一个策略网络来直接输出动作值,所以 DDPG 需要一边学习 Q 网络,一边学习策略网络。
- Q 网络的参数用 $w$ 来表示。策略网络的参数用 $\theta$ 来表示。
- 我们称这样的结构为
Actor-Critic的结构。
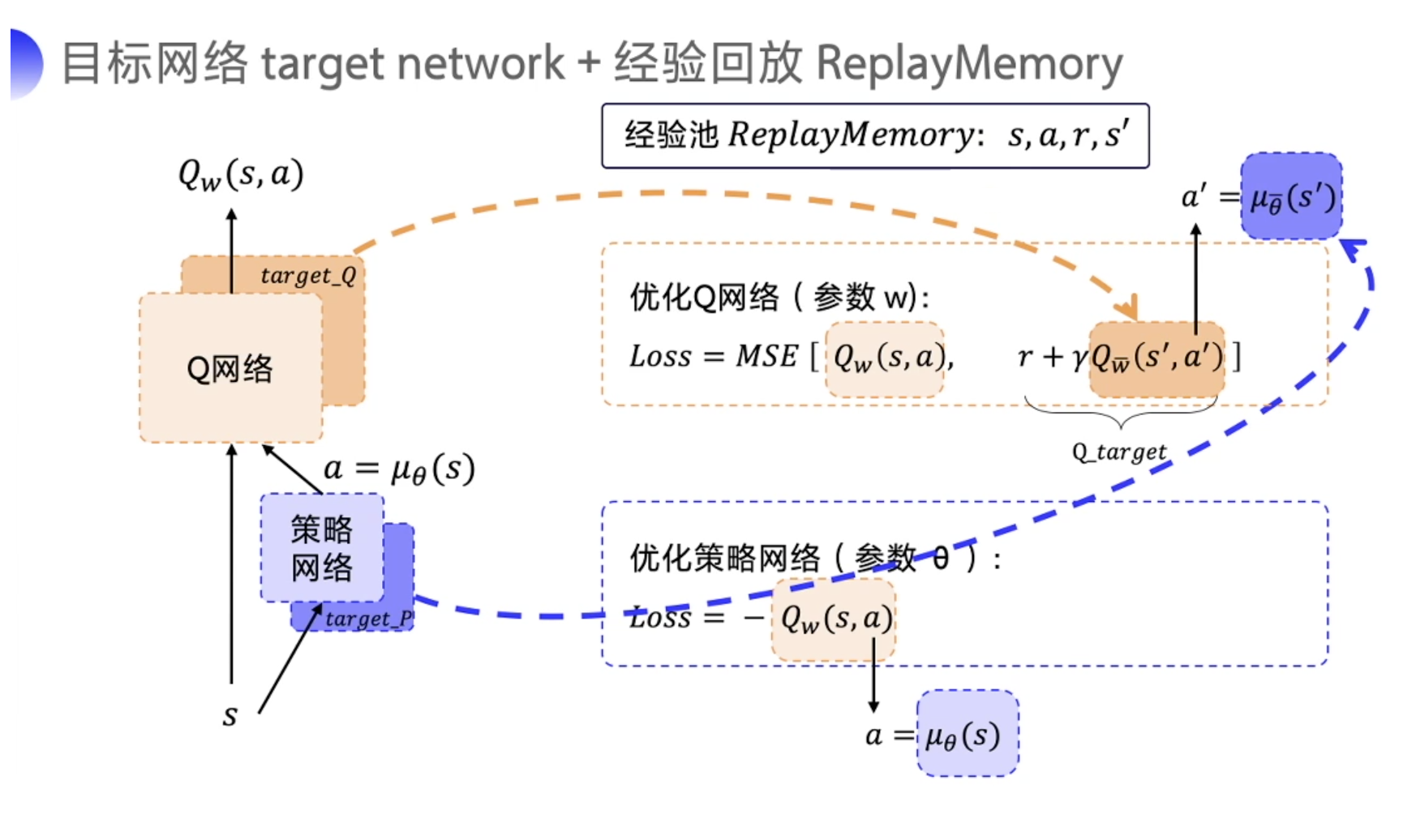
- DDPG 有四个网络,策略网络的 target 网络 和 Q 网络的 target 网络就是颜色比较深的这两个,它只是为了让计算 Q_target 的时候能够更稳定一点而已。因为这两个网络也是固定一段时间的参数之后再跟评估网络同步一下最新的参数。
- 因为 DDPG 使用了经验回放这个技巧,所以 DDPG 是一个
off-policy的算法。
3)TD3(Twin Delayed DDPG 双延迟深度确定性策略梯度)
截断的双 Q 学习(Clipped Dobule Q-learning) 。TD3 学习两个 Q-function(因此名字中有 “twin”)。TD3 通过最小化均方误差来同时学习两个 Q-function:$Q_{\phi_1}$ 和 $Q_{\phi_2}$。两个 Q-function 都使用一个目标,两个 Q-function 中给出较小的值会被作为如下的 Q-target:
延迟的策略更新(“Delayed” Policy Updates) 。相关实验结果表明,同步训练动作网络和评价网络,却不使用目标网络,会导致训练过程不稳定;但是仅固定动作网络时,评价网络往往能够收敛到正确的结果。因此 TD3 算法以较低的频率更新动作网络,较高频率更新评价网络,通常每更新两次评价网络就更新一次策略。
目标策略平滑(Target Policy smoothing) 。TD3 引入了 smoothing 的思想。TD3 在目标动作中加入噪音,通过平滑 Q 沿动作的变化,使策略更难利用 Q 函数的误差。
目标策略平滑化(一种正则化方法)的工作原理如下:
其中 $\epsilon$ 本质上是一个噪声,是从正态分布中取样得到的,即 $\epsilon \sim N(0,\sigma)$。
4月20日
研读Openai gym Wiki中大佬们的代码。
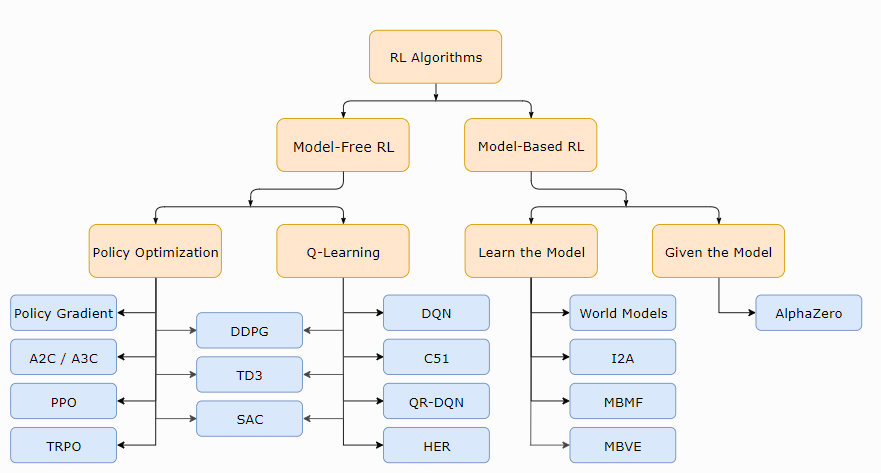
深度强化学习算法伪代码汇总:
1)DQN

2)PPO
![BWQ@UA}78G_T[VI0P_EC]8B.png](https://pic.rmb.bdstatic.com/bjh/e0beb3014d9953aaf1deac573d782228.png)
3)A3C

4)DDPG

4月21日
把深度强化学习主要算法过了一遍,也能跑通gym上的环境,发现自己并不能根据算法进行代码的复现,而且对一些深度学习网络模型也不是很了解,决定从今天开始啃《动手学深度学习》(Pytorch版本)

5月9日
从今天开始接着啃强化学习了🤖

DRL代码整理
MDP
1 | import numpy as np |
1 | import numpy as np |
Model-free Prediction
代码地址:Hands-on-RL / 第3章-马尔可夫决策过程.ipynb
代码地址:Hands-on-RL / 第5章-时序差分算法.ipynb
Model-free Control
代码地址:
RL_code/Model-free Control/Sarsa at main · panmingyan/RL_code (github.com)
代码地址:
RL_code/Model-free Control/QLearning at main · panmingyan/RL_code (github.com)
Policy Gradient
代码地址:
RL_code/PolicyGradient at main · panmingyan/RL_code (github.com)
PPO
代码地址:
RL_code/PPO at main · panmingyan/RL_code (github.com)
DQN
代码地址:
RL_code/DQN at main · panmingyan/RL_code (github.com)
DoubleDQN
代码地址:
RL_code/DoubleDQN at main · panmingyan/RL_code (github.com)
D3QN
代码地址:
DRL_code/D3QN at main · panmingyan/DRL_code (github.com)
A3C
代码地址:
DRL_code/A3C at main · panmingyan/DRL_code (github.com)
DDPG
代码地址:
DRL_code/DDPG at main · panmingyan/DRL_code (github.com)
TD3
代码地址: