- ZJUT研究生 | 人工智能方向 | 目前在杭州
- 科技门徒 | 软硬件兼攻 | 前后端兼修
- 科技竞赛爱好者 | 热爱一切高新科技
- 最喜欢的一句话:你要对发生在你身上的事情抱有低期望,不能盲目乐观自己会有好运。普通人很难遇到好运,反而任何一个小意外,就足以把你难倒。但是你不能放弃,必须多尝试,多去做,尽量参与,这样才可能会有改变。
- 最近在看:《风骚律师 第三季》
新 / 老 / 佬 同学们欢迎加我的QQ/微信:(记得备注姓名,我会记得你 :-)
微信


新 / 老 / 佬 同学们欢迎加我的QQ/微信:(记得备注姓名,我会记得你 :-)
微信

多智能体强化学习历程
单纯测试一下还好不好用
对VDN、QMIX、QTRAN深度强化学习算法进行简要介绍
智能博弈领域已逐渐成为当前AI研究的热点之一,游戏AI领域、智能兵棋领域都在近年取得了一系列的研究突破。但是,游戏 AI 如何应用到实际的智能作战推演依然面临巨大的困难。综合分析智能博弈领域的国内外整体研究进展,详细剖析智能作战推演的主要属性需求,并结合当前最新的强化学习发展概况进行阐述。从智能博弈领域主流研究技术、相关智能决策技术、作战推演技术难点3个维度综合分析游戏AI发展为智能作战推演的可行性,最后给出未来智能作战推演的发展建议。以期为智能博弈领域的研究人员介绍一个比较清晰的发展现状并提供有价值的研究思路。
在深度强化学习中,联盟训练通过引入主智能体的“陪练”,发现主智能体策略的缺点,帮助其得到更快的提升。本文通过对模型特征和模型池多样性的建模,并基于此提升联盟模型池的多样性,引导克制主智能体的多种策略并提升主智能体的强度;同时,模型池的多样性也可以作为训练目标,为游戏AI的线上应用提供更多选择。
本文以障碍物随机分布的复杂环境下多无人机攻防对抗机动决策为研究背景,构建了攻防双方运动模型及雷达探 测模型,将TD3(Twin Delayed Deep Deterministic policy gradient) 算法扩展到多智能体领域中解决MADDPG(Multi-Agent Deep Deterministic Policy Gradient)算法存在值函数高估的问题;在此基础上,为了提升算法学习效率,结合优先经验回放机制(PER)提出了多智能体双延迟深度确定性策略梯度PER-MATD3(Prioritized Experience Replay Multi-Agent Twin Delayed Deep Deterministic policy gradient algorithm)算法。 通过仿真实验表明本文所设计的方法在多无人机攻防对抗机动决策问题中具有较好的对抗效果, 并通过对比验证了PER-MATD3算法相较其它算法在收敛速度和稳定性方面的优势。

整理了在学习深度强化学习过程中的算法和代码(使用Pytorch实现)
代码库地址:panmingyan/DRL_code: Deep Reinforcement Learning Code (github.com)
使用Python实现扇贝精听功能,可以对英文原著进行逐句精听,语音合成使用百度AI开放平台。

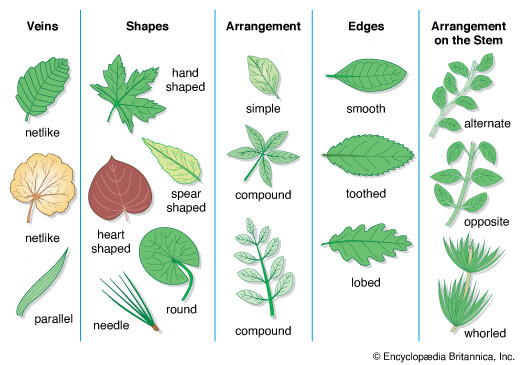
Kaggle竞赛——Classify Leaves
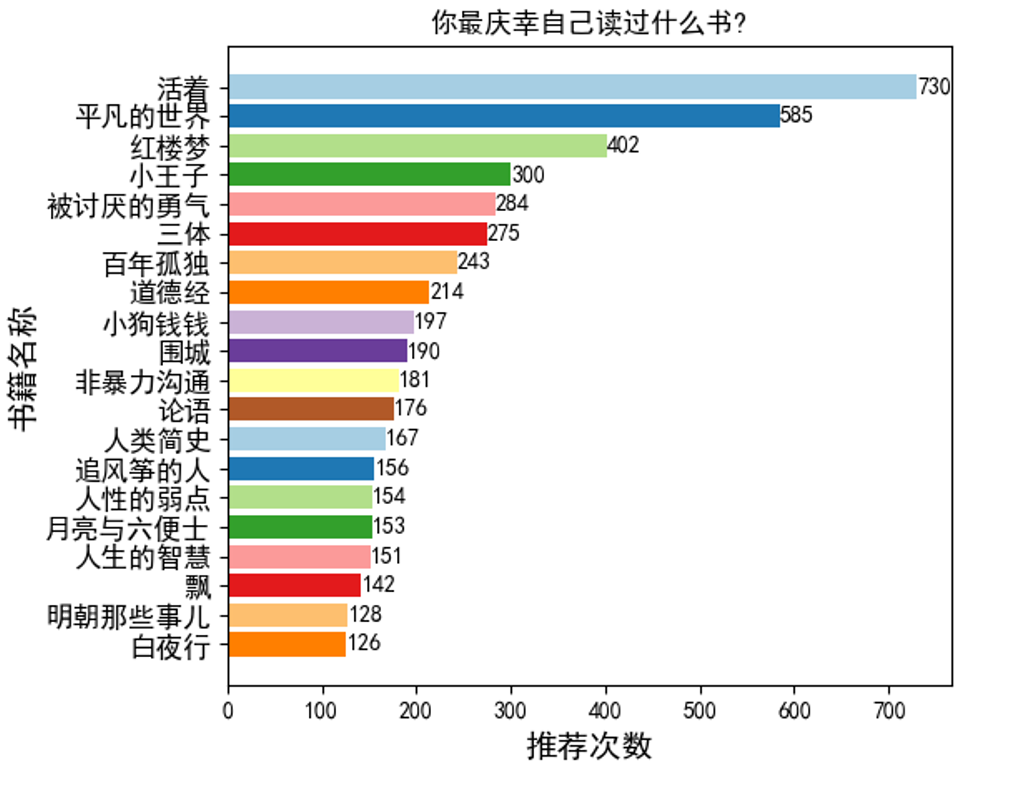
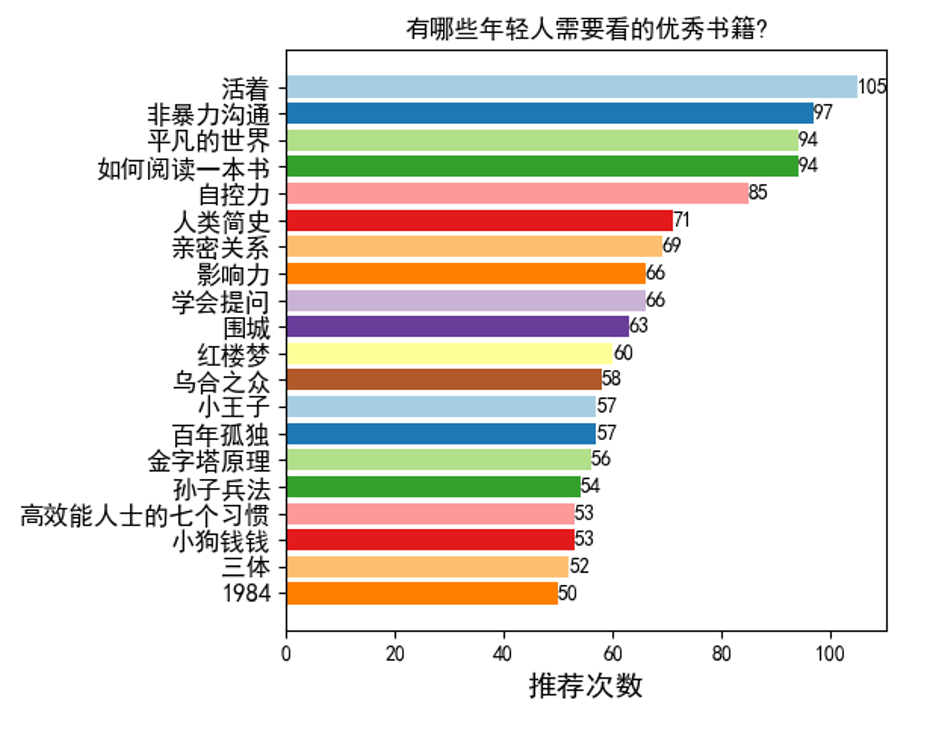
分别爬取知乎问题 “你最庆幸自己读过什么书?”(15477个回答)和“有哪些年轻人需要看的优秀书籍?”(1961个回答),统计了推荐次数前二十的书籍,并使用Matplotlib自动生成柱状图,结果如下:

Kaggle竞赛——California房价预测

提升自己对神经网络结构理解、代码复现的能力。

对莫烦老师的DQN倒立摆代码做了逐行解析

记录自己强化学习学习过程


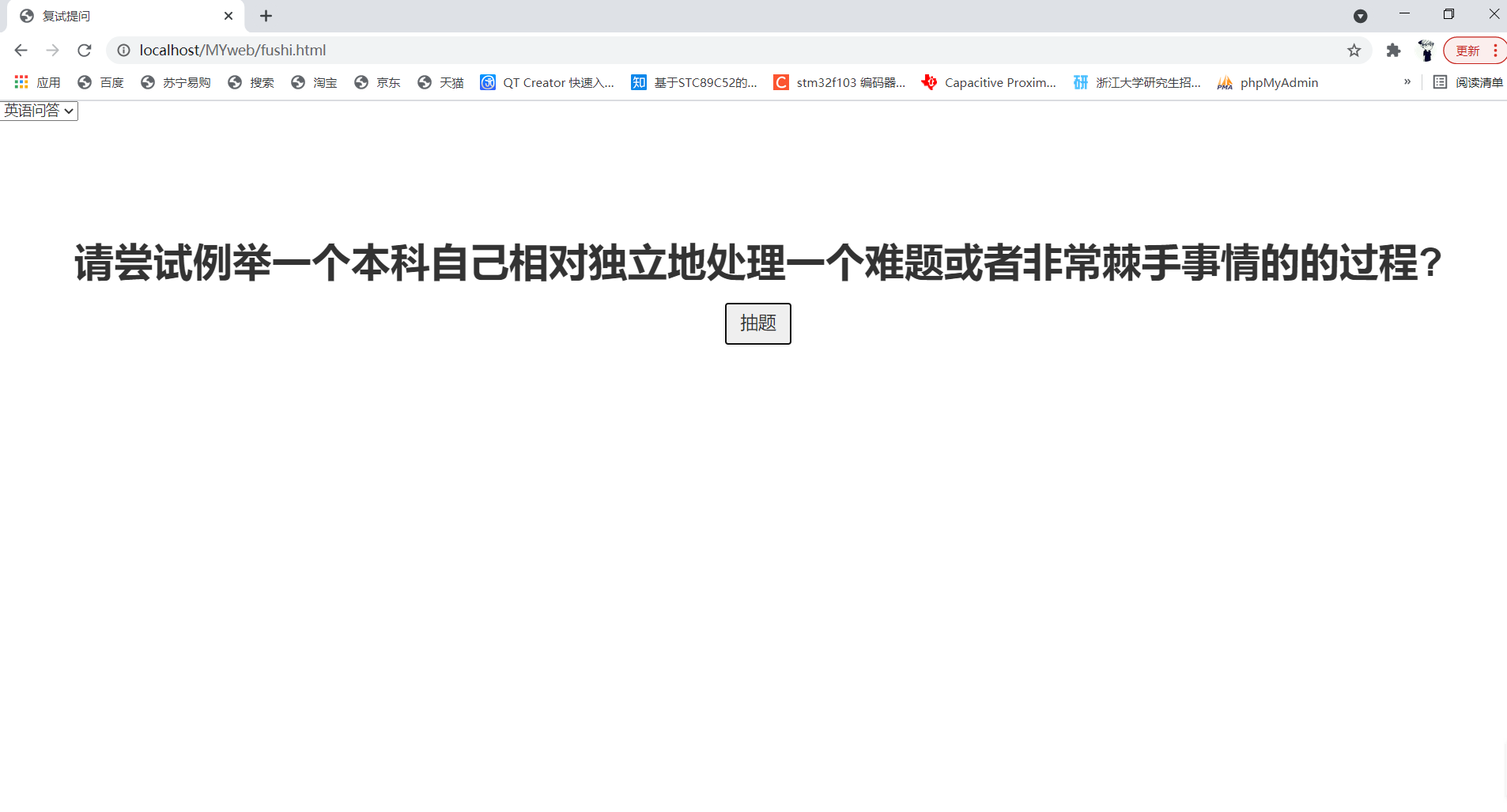
用js写了一个简易复试问答系统

数据竞赛平台Kaggle上关于泰坦尼克号幸存者预测的比赛。

通过Google Colab平台训练yolov5模型,实现对可乐罐的识别

迁移学习是将一个预训练的模型通过截断和重构后,用在别的任务中。

利用预先训练好的模型进行图像识别
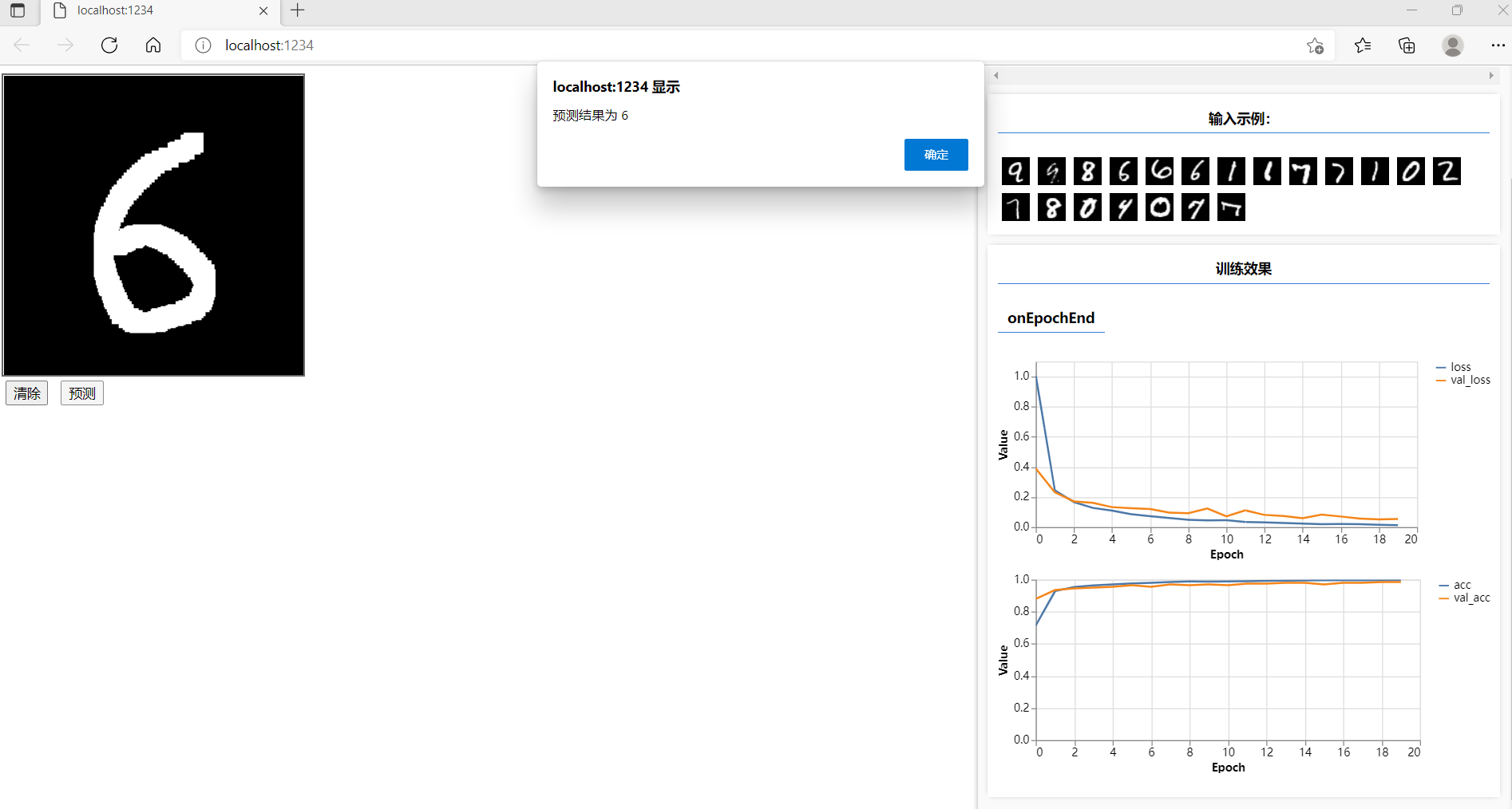
利用卷积神经网络+canvas实现了手写数字识别

在这里,你将对我的本科毕业设计有更深的认识。
爬取知乎“生活中有哪些必备的知识技能需要了解?”问题下1015条回答,进行词频统计,结果如下:

爬取知乎“有哪些好看的高智商悬疑电影?”问题下全部2142条回答,提取关键词并绘制词云。结果如下:

为了练习Python的面向对象编程,我用Python实现了Q宠大乐斗(文字版)

爬取知乎“有哪些好看的美剧推荐 ?”问题下1283个回答,进行词频统计,并绘制词云。
结果如下:


在英语学习的过程中,我自己整理了一些容易混淆单词。

数据挖掘过程中常用的操作